과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



LLMs, RAG, & the missing storage layer for AI
GPT-3와 그 후속 모델들은 자연어 처리, 기계 번역, 가상 어시스턴트, 콘텐츠 생성 등 다양한 응용 분야에서 중심 역할을 하고 있습니다. 이러한 모델들은 놀라운 정확도로 인간과 유사한 텍스트를 이해하고 생성할 수 있는 능력으로 인해 중요한 발전을 이루었습니다.
그러나 이 AI 혁명의 표면 아래에는 중요한 누락된 요소가 있습니다: 저장 계층(storage layer). 이 누락된 구성 요소는 AI 시스템의 더 큰 능력을 해제할 수 있는 잠재력을 가지고 있다고 제안됩니다.
요컨대, 생성 AI와 LLMs는 인간과 유사한 텍스트 생성과 이해에서 중요한 진전을 이루었지만, 저장 계층이라는 아직 탐구되지 않은 분야가 있습니다. 이 계층은 학습한 지식을 저장할 수 있는 저장소 역할을 할 수 있으며, AI 시스템이 정보를 생성뿐만 아니라 저장하고 검색할 수 있게 하여 더 다양하고 효과적인 시스템을 만들 수 있습니다.
LLMs에 대한 객관적인 진실
LLM 리프레셔로 맥락을 설정해봅시다. 다음은 지난 몇 년 동안 일어난 몇 가지 주요 사항입니다.
LLMs는 지금까지 만들어진 가장 고도로 발전한 AI 시스템입니다
LLMs와 파생 작품은 많은 산업과 연구 분야를 혁명적으로 바꿀 잠재력을 가지고 있습니다. 예를 들어, 더 자연스럽고 매력적인 사용자 인터페이스를 만들거나, 새로운 교육 도구를 개발하고, 기계 번역의 정확성을 향상시킬 수 있습니다. 또한 새로운 아이디어와 통찰력을 생성하고, 언어와 언어학 분야에서 새로운 방향을 열 수 있는 새로운 형태의 예술과 문학을 창조할 수도 있습니다.
이러한 모델들은 이전에 볼 수 없었던 속도로 벤치마크에서 인간 수준을 압도하고 있습니다:

이 시스템들은 자신 있게 거짓말을 합니다.
LLMs는 매우 고도로 발전해 있어서 대부분의 경우 생성된 텍스트와 인간의 응답을 구분하기가 거의 불가능합니다. 그러나 이러한 시스템들은 다양한 수준의 ‘환각’에 시달립니다. 다르게 표현하면, 이 시스템들은 자신 있게 거짓말을 하고, 그 거짓말은 인간 수준의 텍스트 생성 능력 덕분에 상당히 설득력 있게 느껴집니다.

한눈에 보면 이 결과들은 인상적으로 보이지만 링크를 따라가면 모두 404 에러로 이어집니다. 이것은 여러 가지 수준에서 위험합니다:
- 첫째, 이 링크들이 설득력 있게 보이기 때문에 확인하지 않고 그냥 인용으로 받아들일 수 있습니다.
- 최선의 경우는 첫 번째 링크를 확인하고 404로 이어진다는 것을 깨달은 후 다른 링크도 확인할 것입니다.
- 하지만 최악의 경우는 첫 번째 링크만 실제로 존재하고 그것만 확인한다면, 모든 링크가 유효하다고 믿게 될 것입니다.
이것은 환각의 한 예일 뿐, 더 미묘한 다른 예들도 있습니다, 예를 들면 단순히 사실을 지어내는 것과 같은 경우가 있습니다.
가장 강력한 LLMs는 여전히 ‘블랙 박스’입니다
개인적으로 저는 딥러닝 전반에 ‘블랙 박스’라는 용어가 남발되는 것을 좋아하지 않습니다. 대부분의 이 모델들은 쉽게 분석하고 수정할 수 있기 때문입니다. 실제로, 원래 발표된 모델의 수정된 버전이 더욱 인기 있고 유용하게 사용되고 있습니다. 해석 가능성은 역사적으로 어려운 문제였지만, 그것만으로 이 모델들을 블랙 박스라고 부르기에는 부족합니다. 그러나 LLMs의 경우는 다릅니다. 가장 강력한 LLMs는 폐쇄 소스로, API 요청을 통해만 접근할 수 있습니다. 또한, 높은 훈련 비용과 독점 데이터셋 때문에, 결과를 재현할 만한 충분한 자원이나 엔지니어링 전문성이 부족합니다. 이러한 상황은 블랙 박스의 정의에 맞습니다.

응답 중심 시스템 대 표현 중심 시스템
프롬프트 기반 방식에서는 당신(또는 당신의 사용자들)의 질문에 바로 응답을 생성하기 위해 LLMs에 의존합니다. LLMs를 사용해 응답을 생성하는 것은 매우 강력하고, 시작하기도 쉽습니다. 그러나 이러한 시스템의 생명주기에 대한 어떠한 측면도 제어할 수 없다는 것을 깨달을 때, 곧이어 불안해질 수 있습니다. 위에서 언급한 ‘객관적인 진실’과 결합되면, 이는 곧 재앙으로 이어질 수 있는 조합이 될 수 있습니다.
LLMs를 표현용으로 사용하기
LLMs를 처음부터 끝까지 사용하는 대신, 그저 우리의 지식 베이스를 표현하는 데에 사용하면 어떨까요? 그렇게 하려면 가장 명확한 방법은 이 강력한 모델들을 사용해 우리의 데이터베이스를 임베딩하는 것입니다. 이렇게 하면 의미론적 의미를 담은 비구조화된 데이터의 수치적 표현을 얻을 수 있습니다.

이 벡터들은 고차원 공간에서 엔터티들 사이의 관계를 잡아냅니다. 예를 들어, 의미가 유사한 단어들이 서로 가까이 위치한 단어 임베딩의 예시가 있습니다.

How do vectors capture relationships?
벡터는 고차원 공간에서 엔터티를 표현함으로써 그들 사이의 기하학적 거리가 어떤 형태의 유사성이나 관계를 반영하도록 합니다. 단어 임베딩이나 다른 유형의 데이터 표현에 있어서, 벡터는 여러 종류의 관계를 포착할 수 있습니다:
- 의미론적 유사성: 의미가 유사한 단어들은 벡터 공간에서 가까울 것입니다. 예를 들어, “고양이”와 “새끼 고양이”의 벡터는 가까이 위치할 것입니다.
- 동의어와 반의어: 동의어는 가까이 위치할 수 있고, 반의어는 그들의 반대되는 의미를 포착하는 특정한 방식으로 위치할 수 있습니다.
- 계층적 관계: 부모-자식이나 부분-전체 관계를 가진 단어들은 이를 반영하는 방식으로 위치할 수 있습니다. 예를 들어, “차량”과 “자동차”는 가까울 것이며, “자동차”는 “차량”의 한 유형입니다.
- 문맥적 관계: 비슷한 문맥에서 자주 나타나는 단어들은 벡터 공간에서 가까울 수 있습니다. 예를 들어, “커피”와 “머그잔”은 자주 함께 나타나기 때문에 가까울 것입니다.
- 기능적 관계: 기능적 관계를 가진 단어들, 예를 들어 “펜”과 “쓰다”,는 이러한 관계를 포착하는 방식으로 위치할 수 있습니다.
- 복잡한 관계: 더 복잡한 관계, 예를 들어 유추,도 포착할 수 있습니다. 예를 들어, “남자는 왕에 대한 여자는 여왕”이라는 관계를 벡터 방정식으로 표현할 수 있습니다.
- 시간적 또는 순차적 관계: 일부 경우에는 벡터가 이벤트나 과정의 순서나 연속성을 포착할 수 있습니다.
이러한 관계를 포착하는 데 있어 벡터의 효과성은 그것들이 훈련된 데이터의 품질과 훈련에 사용된 알고리즘에 따라 다릅니다. 고품질의 대규모 데이터셋과 정교한 알고리즘을 사용하면, 높은 정확도로 관계를 포착하는 벡터를 얻을 수 있습니다.
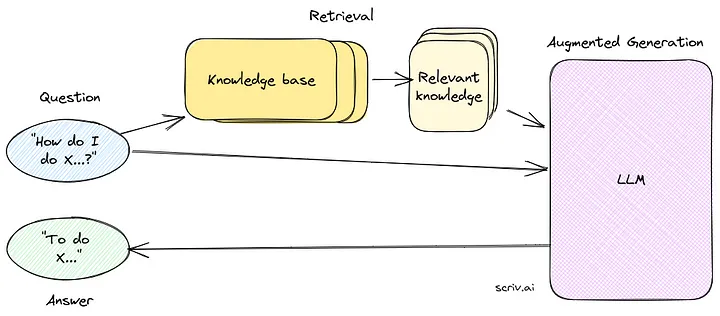
검색 증강 생성(Retrieval Augmented Generation, RAG)
RAG 시스템을 만들기 위해 필요한 모든 요소들을 가지고 있습니다. RAG 설정에서는 프롬프트에서 응답을 생성하기 위해 LLMs를 사용하는 대신, 검색기를 통해 관련된 표현들을 찾아내고, 그것들을 LLM에게 프롬프트하여 응답을 만들도록 합니다.

How does RAG improve LLMs?
검색 증강 생성(Retrieval Augmented Generation, RAG)은 여러 가지 방법으로 언어 모델 머신(Language Model Machines, LLMs)을 개선합니다:
- 문맥적 관련성: RAG는 검색기를 사용하여 데이터베이스나 지식 베이스에서 관련 정보를 가져옵니다. 이로 인해 LLM은 단순히 훈련 데이터를 기반으로 한 것이 아니라 특정하고 관련된 정보를 기반으로 응답을 생성할 수 있어, 출력이 문맥적으로 더 정확해집니다.
- 정보 밀도: 관련 데이터를 가져오는 RAG의 기능으로 인해 LLM은 더 정보 밀도가 높은 응답을 생성할 수 있습니다. 이는 상세한 답변이나 설명이 필요한 작업에 특히 유용합니다.
- 환각 감소: RAG는 실제 데이터를 사용하여 응답을 생성하기 때문에 모델이 ‘환각’하거나 거짓 정보를 생성할 가능성이 줄어듭니다.
- 확장성: RAG는 검색과 생성 과정을 분리할 수 있어, 각 구성 요소를 독립적으로 확장하기 쉽습니다. 이는 계산 자원을 최적화하는 데 유리합니다.
- 유연성: RAG 설정은 모듈식이므로, 특정 요구에 맞게 검색기나 생성기를 다른 모델로 교체할 수 있습니다.
- 해석 가능성: RAG는 검색 가능한 데이터를 사용하여 응답을 생성하기 때문에, 정보의 출처를 추적하기가 더 쉬워, 모델의 해석 가능성이 향상됩니다.
- 실시간 적응성: RAG는 최신 데이터베이스에서 정보를 가져와 실시간으로 새로운 정보에 적응할 수 있어, 독립적인 LLMs보다 더 동적이고 적응력이 있습니다.
- 맞춤화: 검색기를 특정 유형의 정보에 중점을 둬서 미세 조정할 수 있어, 더 맞춤화되고 대상을 잘 맞춘 응답이 가능합니다.
검색 메커니즘을 생성 과정에 통합함으로써, RAG는 LLMs에 대한 더 강건하고 다양한 프레임워크를 제공하며, 그 능력을 향상시키고 제한 사항을 줄입니다.
What are RAG’s limitations?
검색 증강 생성(Retrieval Augmented Generation, RAG)의 여러 가지 제한 사항이 있습니다:
- 계산 부하: 검색 과정은 계산 복잡성을 추가할 수 있어, 시스템이 느려지고 실행 비용이 더 높아질 수 있습니다.
- 데이터 의존성: RAG는 외부 데이터베이스나 지식 베이스에 의존합니다. 이 데이터베이스가 불완전하거나 오류를 포함하고 있다면, 생성된 응답도 부정확할 수 있습니다.
- 튜닝의 복잡성: 검색기와 생성기 모두 미세 조정이 필요하며, 이로 인해 시스템을 최적화하는 것이 복잡하고 시간이 많이 소요될 수 있습니다.
- 제한된 해석 가능성: RAG는 어느 정도 해석 가능성을 향상시키지만, 검색기와 생성기 자체가 복잡한 모델일 경우 모델이 특정 결정을 내린 이유를 완전히 이해하는 것은 여전히 어려울 수 있습니다.
- 문맥 제한: 검색기는 쿼리의 전체 문맥을 항상 완벽하게 포착하지 못할 수 있어, 관련성은 있지만 완전히 정확하지 않은 응답을 생성할 수 있습니다.
- 확장성 문제: 데이터베이스가 커질수록 검색 과정이 느려져 시스템의 전반적인 성능에 영향을 줄 수 있습니다.
- 실시간 제한: RAG는 새로운 정보에 적응할 수 있지만, 의존하는 데이터베이스나 지식 베이스가 항상 최신이 아닐 수 있어 실시간 적응성이 제한될 수 있습니다.
- 일관성 부족: 검색기가 가져온 정보와 생성기가 출력하는 정보 사이에 일관성이 없을 수 있어, 최종 응답에 차이가 생길 수 있습니다.
- 적대적 공격에 대한 취약성: 다른 머신러닝 모델처럼 RAG도 모델의 출력을 조작하려는 적대적 공격에 대한 면역력이 없습니다.
- 윤리적 문제: 사용되는 데이터베이스에 따라 데이터 프라이버시, 편향, 오정보와 관련된 윤리적 문제가 있을 수 있습니다.
이러한 제한 사항에도 불구하고, RAG는 언어 모델의 능력을 향상시키는 유망한 접근법을 제공합니다. 그러나 RAG 시스템을 구현하고 사용할 때 이러한 문제점을 인식하는 것이 중요합니다.
이제 응답을 생성하는 데 사용된 지식 베이스 문서에서 정확한 인용을 제공할 수 있습니다. 응답의 출처를 추적하는 것이 가능해집니다.
도메인 변화
지금까지 RAG를 통해 이룬 것은 LLM에 의존해서 대신 답을 하게 하는 것을 줄인 것입니다. 대신, 이제 우리는 각각 독립적으로 작동하는 다양한 부분을 가진 모듈식 시스템을 갖게 되었습니다:
- 지식 베이스
- 임베딩 모델
- 검색기
- 응답 생성기 (LLM)
이로 인해 도메인이 바뀌어, 검은 상자 형태의 AI에 의존하는 것에서 수십 년의 연구에 기반한 모듈식 구성 요소로 넘어갔습니다.
“잘 작동하지 않을 때는 AI, 작동하기 시작하면 컴퓨터 과학이다”
이 말은 거의 10년 전에 처음 들었을 때부터 계속 생각이 나는데, 이것이 에릭 슈미트(Eric Schmidt)의 말인 것 같지만, 그 정확한 강의를 찾을 수 없었습니다.
일반적인 생각은 이제 우리가 문제의 도메인을 그렇게 바꾸었기 때문에 검색기가 시스템의 중심이 되고, 정보 검색, 랭킹 등과 같은 컴퓨터 과학의 하위 도메인에서의 연구를 활용할 수 있게 되었다는 것입니다.
Retrieval Augmented Generation(RAG)를 통해 언어 모델 머신(LLM)에 의존하는 것을 줄이고, 대신 여러 독립적인 모듈로 구성된 시스템을 사용하게 된 것에 대해 설명하고 있습니다. 이 시스템은 지식 베이스, 임베딩 모델, 검색기, 그리고 응답 생성기(LLM)로 구성되어 있습니다.
이러한 변화로 인해, 기존에 ‘검은 상자’ 형태의 AI에 의존하던 것에서 벗어나, 수십 년간의 연구에 기반한 모듈식 구성 요소를 사용하게 되었다고 설명하고 있습니다.
또한, “잘 작동하지 않을 때는 AI, 작동하기 시작하면 컴퓨터 과학이다”라는 명언을 인용하며, 이제 검색기가 시스템의 중심 역할을 하게 되어 정보 검색, 랭킹 등과 같은 컴퓨터 과학의 하위 분야에서의 연구를 활용할 수 있게 되었다고 말하고 있습니다.
돈을 많이 써야 하나요?
비용은 여러 요인에 따라 달라집니다. 이제 배포된 ML 시스템이 마주치는 일반적인 문제와 이러한 생성 AI 접근법이 그것들을 어떻게 해결하려고 하는지에 대해 주목해 봅시다.
- 해석 가능성(Interpretability) — 심층 신경망을 자신 있게 해석할 방법은 현재까지 없지만, 이는 활발한 연구 분야입니다. LLMs를 해석하는 것은 더욱 어렵습니다. 그러나 RAG 설정에서는 응답을 단계적으로 구축함으로써 결정의 원인에 대한 통찰을 얻을 수 있습니다.
- 모듈성(Modularity) — 모듈식 시스템은 end-to-end API 접근 가능 모델에 비해 많은 장점이 있습니다. 우리의 경우, 지식 베이스에 어떤 것이 들어가고 시간이 지남에 따라 어떻게 업데이트되는지, 검색기와 랭킹 알고리즘의 구성, 그리고 최종 응답을 생성하기 위해 이 정보를 어떤 모델에 공급하는지에 대한 세밀한 제어가 가능합니다.
- (재)훈련 비용(Re-Training Cost) — LLMs(지역 모델 포함)의 가장 큰 문제는 대규모의 데이터와 인프라 요구 사항입니다. 이로 인해 새로운 데이터가 들어올 때마다 그것들을 재훈련하는 것은 거의 불가능에 가깝습니다.
따라서, 비용은 여러 요인, 예를 들어 시스템의 복잡성, 필요한 데이터의 양, 사용되는 알고리즘과 기술, 그리고 시간에 따라 달라질 수 있습니다. 모듈식 접근법은 일부 문제를 해결할 수 있지만, 그 자체로도 비용이 발생할 수 있습니다.
예를 들어, 훈련이 끝난 후(또는 더 구체적으로 데이터셋 생성 날짜 마감 후)에 발생한 최근의 사건을 고려해 봅시다. 여기에는 몇 일 전에 발생한 사건부터 몇 개월 전에 발생한 사건에 대한 질문들이 있으며, 이러한 질문들은 ChatGPT에게 물어볼 수 있습니다.
이러한 상황에서는 다음과 같은 문제가 발생할 수 있습니다:
- 데이터 미비: 훈련 데이터에 최근의 사건이 포함되어 있지 않을 경우, 모델은 그에 대한 정확한 정보를 제공할 수 없습니다.
- 시간적 제약: 데이터셋이 특정 시점에서 잘라진 경우, 그 이후의 사건에 대한 정보는 반영되지 않습니다.
- 동적 적응성 부족: 일반적인 LLMs는 새로운 데이터에 실시간으로 적응하지 못합니다. 그러나 RAG 같은 시스템은 지식 베이스를 실시간으로 업데이트할 수 있어 이러한 문제를 어느 정도 해결할 수 있습니다.
- 비용 문제: 실시간으로 지식 베이스를 업데이트하려면 추가적인 비용이 발생할 수 있습니다.
따라서, 최근 사건에 대한 질문을 처리하려면 시스템의 동적 적응성과 비용 문제를 고려해야 할 수 있습니다.

정보의 변화가 빠른 비즈니스 하위 분야에서 LLM이 특별히 조정되었다면, 이 모델들은 아주 빠르게 구식이 될 수 있습니다.
만약 같은 시스템이 RAG 시스템에 의존한다면, 지식 베이스만 업데이트하면 됩니다. 즉, 새로운 이벤트나 정보를 임베딩 모델에 넣고 나면 나머지는 검색기가 처리합니다. 반면에, LLM은 직접 응답을 생성하는 시스템에서는 새로운 데이터에 대해 재훈련이 필요합니다.
결론적으로, 이 방법은 더욱 세밀한 제어와 모듈성을 제공할 뿐만 아니라, 새로운 정보가 들어왔을 때 업데이트하는 데 드는 비용도 훨씬 저렴하다는 것이 입증되었습니다.
미세 조정(Finetuning) 대비 RAG
도메인 특정 데이터에 모델을 미세 조정하는 것과 일반 모델을 RAG에 사용하는 것 중 무엇이 더 나은지에 대한 논쟁은 의미가 없습니다. 물론 이상적으로는 두 가지를 모두 원합니다. 도메인의 맥락을 더 잘 이해하는 미세 조정된 모델은 문맥에 맞는 어휘를 사용하여 더 나은 “일반적인” 응답을 제공할 것입니다. 그러나 응답의 더 나은 제어와 해석 가능성을 위해서는 RAG 모델이 필요합니다.
AI 네이티브 데이터베이스의 필요성
이 시점에서는 잘 관리된 지식 베이스가 필요하다는 것이 분명합니다. 많은 전통적인 해결책이 있지만, AI 솔루션에 맞게 이를 재고려해야 합니다. 주요 요구 사항은 다음과 같습니다:
- AI에는 대량의 데이터가 필요합니다.
- 모델은 멀티모달로 발전하고 있습니다. 따라서 데이터도 그에 맞춰야 합니다.
- 확장이 비용을 지나치게 높게 만들어서는 안 됩니다.
- 멀티모달성은 다음 단계의 중요한 부분이며, 대부분의 LLM 제공자는 이미 멀티모달 기능을 지원하거나 테스트 중입니다.
이 모든 것을 고려할 때, ML의 새로운 하위 도메인을 만들 필요는 없습니다. 그러므로 기존 도구와 인터페이스를 활용하는 것이 가장 이상적입니다.
Can RAG adapt to different languages?
Retrieval Augmented Generation (RAG)은 기본적인 지식 베이스와 검색기가 다양한 언어의 데이터를 처리할 수 있도록 구성되어 있다면, 다른 언어에도 적응할 수 있습니다. 다양한 언어에서 RAG 시스템의 효과성은 대부분 지식 베이스에 있는 다국어 데이터의 품질과 범위, 그리고 검색기가 언어 간에 관련 정보를 정확하게 가져올 수 있는 능력에 따라 달라집니다.
다른 언어에 RAG를 적응시키기 위한 몇 가지 고려 사항은 다음과 같습니다:
- 다국어 지식 베이스: 지식 베이스는 다양한 사용자를 대상으로 하기 위해 여러 언어의 정보를 포함해야 합니다.
- 언어에 중립적인 검색기: 검색기는 다양한 언어로 된 쿼리를 이해하고 그에 따라 관련 정보를 가져와야 합니다.
- 번역 레이어: 시스템이 본래 다국어를 지원하지 않는다면, 쿼리와 응답을 언어 간에 변환할 수 있는 번역 레이어를 추가할 수 있습니다.
- 미세 조정: RAG에서 사용되는 언어 모델 머신(LLMs)은 다국어 데이터에 미세 조정될 수 있어 성능을 향상시킬 수 있습니다.
- 문화적 및 맥락적 민감성: 시스템은 언어마다 다를 수 있는 문화적이고 맥락적 미묘함에 민감해야 합니다.
이러한 요소를 고려하면, RAG 시스템은 여러 언어의 사용자에게 효과적으로 서비스를 제공할 수 있게 적응할 수 있습니다.
How does RAG handle misinformation?
Retrieval Augmented Generation (RAG) 시스템이 오정보를 어떻게 처리하는지는 대부분 그 하위에 있는 지식 베이스의 품질과 신뢰성에 달려 있습니다. RAG는 이 지식 베이스에서 정보를 검색하여 응답을 생성하기 때문에, 응답의 정확성은 저장된 정보의 정확성에 직접적으로 연결됩니다. RAG가 오정보를 어떻게 처리할 수 있는지 몇 가지 방법은 다음과 같습니다:
- 선별된 지식 베이스: 지식 베이스가 신뢰할 수 있는 출처에서 선별되었다면 오정보의 위험을 최소화할 수 있습니다.
- 정기적인 업데이트: 지식 베이스를 최신 상태로 유지하면 오래되거나 잘못된 정보를 수정할 수 있습니다.
- 팩트 체킹 메커니즘: 자동 또는 수동의 팩트 체킹 메커니즘을 구현하면 지식 베이스에 추가되기 전에 정보를 검증할 수 있습니다.
- 사용자 피드백: 사용자가 잘못되거나 오해를 불러일으키는 정보를 신고할 수 있도록 하면 수정이 필요한 부분에 대한 중요한 통찰을 얻을 수 있습니다.
- 투명성: 검색된 정보에 대한 인용문이나 출처를 제공하면 사용자가 직접 사실을 검증할 수 있습니다.
- 맥락 이해: 고도화된 RAG 시스템은 쿼리가 제기된 맥락을 이해할 수 있도록 설계될 수 있으며, 이는 사실과 의견이나 추측을 구별하는 데 도움이 될 수 있습니다.
- 감사 추적: 지식 베이스에 이루어진 변경 사항에 대한 기록을 유지하면 오정보의 원천을 추적할 수 있습니다.
- 윤리 지침: 정보 검색과 응답 생성에 대한 윤리 지침을 설정하면 시스템이 오정보의 확산을 피하는 데 도움이 될 수 있습니다.
- 모니터링 및 검토: 시스템 성능의 정기적인 모니터링과 검토는 오정보와 관련된 문제를 식별하고 수정하는 데 도움이 될 수 있습니다.
이러한 기능과 안전장치를 포함시킴으로써, RAG 시스템은 오정보를 처리하는 데 더 잘 갖춰질 수 있습니다. 그러나 어떤 시스템도 100% 완벽할 수는 없으며, 오정보의 확산 위험을 최소화하기 위한 지속적인 노력이 필요하다는 점을 명심해야 합니다.
LanceDB: the AI Native, multi-modal, & embedded vector Database
LanceDB는 벡터 기반 데이터를 다루기 위해 특별히 설계된 데이터베이스 분야에서 흥미로운 발전입니다. 이것이 유용한 이유는 다음과 같습니다:
- 벡터 검색: 기존의 데이터베이스는 머신러닝과 AI 애플리케이션에서 중요한 벡터 검색에 최적화되어 있지 않습니다. LanceDB는 벡터 검색에 특화된 지원을 제공하여 이러한 공백을 채웁니다.
- 영구 저장: 영구 저장 기능이 포함되어 있어 시스템이 종료된 후에도 데이터를 유지할 수 있습니다. 이것은 장기 프로젝트와 애플리케이션에 필수적입니다.
- 간단한 검색: LanceDB는 임베딩의 검색을 간단하게 만듭니다. 이것은 자연어 처리, 이미지 인식 및 다른 머신러닝 작업에서 특히 유용합니다.
- 필터링 기능: 데이터베이스는 고급 필터링 옵션을 허용하여 대규모 데이터셋을 쉽게 걸러내고 가장 관련성 있는 정보를 찾을 수 있게 합니다.
- 임베딩 관리: 큰 데이터셋을 다룰 때 임베딩을 관리하는 것은 복잡한 작업일 수 있습니다. LanceDB는 임베딩 관리를 위한 전용 플랫폼을 제공하여 이를 단순화합니다.
- 오픈 소스: 오픈 소스라는 것은 커뮤니티가 그 개발에 기여할 수 있음을 의미하며, 이로 인해 시간이 지남에 따라 더욱 강력하고 다양한 기능을 갖출 수 있습니다.
- 통합: 머신러닝과 AI를 염두에 두고 설계되었기 때문에 기존의 ML/AI 파이프라인과 통합하기가 더 쉬울 것입니다.
- 확장성: LanceDB는 확장성을 염두에 두고 만들어졌으므로, 데이터 양이 증가해도 성능 저하가 크지 않습니다.
이러한 기능을 제공함으로써, LanceDB는 오늘날의 머신러닝과 AI 환경에서 점점 더 중요해지는 벡터 기반 데이터를 효율적이고 효과적으로 관리할 수 있는 방법을 제공합니다.

Can LanceDB handle real-time updates?
LanceDB가 실시간 업데이트를 처리할 수 있는지 여부는 그 아키텍처와 제공하는 특정 기능에 따라 다릅니다. 일반적으로 벡터 검색과 머신러닝 애플리케이션을 위해 설계된 데이터베이스는 관련성과 유용성을 유지하기 위해 실시간 업데이트와 같은 기능을 중요시합니다. 다음은 몇 가지 고려 사항입니다:
- 인메모리 저장: LanceDB가 인메모리 저장을 사용한다면, 일반적으로 읽기-쓰기 작업이 더 빠른 인메모리 데이터베이스의 특성상 더 빠른 실시간 업데이트를 제공할 수 있을 것입니다.
- 동시성 제어: 여러 실시간 업데이트를 충돌이나 불일치 없이 처리하기 위해 효과적인 동시성 제어 메커니즘이 필요합니다.
- 이벤트 주도 아키텍처: 이벤트 주도 아키텍처를 사용하면 LanceDB가 새로운 데이터가 들어올 때 자동으로 실시간으로 레코드를 업데이트할 수 있습니다.
- 확장성: 데이터베이스는 성능에 큰 영향을 미치지 않고 점점 늘어나는 실시간 업데이트의 양을 처리할 수 있도록 확장 가능해야 합니다.
- 인덱싱: 효율적인 인덱싱 전략은 레코드를 찾아 업데이트하는 데 걸리는 시간을 줄여 실시간 업데이트를 더 쉽게 관리할 수 있게 합니다.
- API 지원: LanceDB가 강력한 API 지원을 제공한다면, 다른 시스템과 통합하여 실시간 업데이트를 자동으로 가져올 수 있을 것입니다.
- 데이터 검증: 실시간 업데이트에는 데이터베이스에 정확하고 관련성 있는 데이터만 추가되도록 강력한 데이터 검증 메커니즘이 필요합니다.
- 장애 허용성: 시스템은 업데이트가 시스템 실패 중에 손실되지 않도록 장애 허용성이 있어야 실시간 업데이트를 효과적으로 처리할 수 있습니다.
- 문서화: LanceDB의 공식 문서를 확인하여 실시간 업데이트가 명시적으로 지원되는지와 어떻게 구현할 수 있는지 확인하세요.
이러한 기능을 염두에 두고 설계되었다면, LanceDB는 실시간 업데이트를 잘 처리할 수 있을 것입니다. 그러나 가장 정확한 정보를 얻기 위해 공식 문서를 참조하거나 개발자에게 문의하는 것이 가장 좋습니다.
np.array — The OG vectorDB
NumPy 라이브러리의 np.array는 배열과 수학 연산을 처리하는 데 있어 파이썬에서 매우 강력한 도구입니다. 이것은 파이썬 기반의 데이터 과학과 머신러닝 애플리케이션에서 벡터를 다루는 “원래의” 방법으로 자주 간주됩니다. 그러나 np.array를 벡터 데이터베이스로 사용하는 것은 장단점이 있습니다.
장점:
- 단순성:
np.array를 사용하는 것은 간단하며 별도의 데이터베이스 설정이 필요하지 않습니다. - 속도: NumPy는 수치 연산에 최적화되어 있어 작은 크기에서 중간 크기의 배열에 대해 매우 빠릅니다.
- 유연성:
np.array에서 다양한 수학 연산을 쉽게 수행할 수 있습니다. - 호환성: 파이썬 라이브러리이므로 다른 파이썬 기반 도구와 라이브러리와 쉽게 통합할 수 있습니다.
단점:
- 확장성:
np.array는 매우 큰 데이터셋에 대한 확장 가능한 솔루션으로 설계되지 않았습니다. 데이터가 커지면 메모리 제한에 부딪힐 것입니다. - 지속성: 데이터베이스와 달리
np.array의 데이터는 지속적이지 않습니다. 애플리케이션이 재시작되면 디스크에 저장하지 않은 경우 모든 데이터를 잃게 됩니다. - 동시성: NumPy는 동시 읽기-쓰기에 대한 내장 지원을 제공하지 않아, 여러 사용자나 실시간 애플리케이션에서 제한이 될 수 있습니다.
- 내장 인덱싱 없음: 벡터를 검색할 수는 있지만, 데이터베이스처럼 내장 인덱싱이 없어 데이터셋이 커짐에 따라 검색 작업이 느려질 수 있습니다.
- 기능 부족: LanceDB와 같은 벡터 저장을 위해 설계된 데이터베이스는 고급 필터링, 장애 허용성, 실시간 업데이트와 같은 추가 기능을 제공하는데, 이러한 기능은 단순한
np.array에서는 얻을 수 없습니다.
예시:
np.array에 벡터를 저장하고 유사한 벡터를 찾는 간단한 예시입니다:
import numpy as np
# 벡터의 배열 생성
vectors = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 쿼리 벡터
query_vector = np.array([1, 2, 3])
# 유사성 계산 (예: 유클리디안 거리)
distances = np.linalg.norm(vectors - query_vector, axis=1)
# 가장 유사한 벡터의 인덱스 찾기
closest_index = np.argmin(distances)
# 가장 유사한 벡터 검색
closest_vector = vectors[closest_index]
print("가장 가까운 벡터는:", closest_vector)
요약하면, np.array는 특정 사용 사례에 대해 강력한 도구일 수 있지만, 모든 애플리케이션에 대한 완전한 벡터 데이터베이스로는 충분하지 않을 수 있습니다.
import numpy as np
import pandas as pd
# Assuming you have already defined your data and embedding_model
data = [...] # Your data
embedding_model = [...] # Your embedding model function
cosine_sim = [...] # Your cosine similarity function
# Creating and saving the DataFrame
embeddings = []
ids = []
for i, item in enumerate(data):
embeddings.append(embedding_model(item))
ids.append(i)
df = pd.DataFrame({"id": ids, "embedding": embeddings})
df.to_pickle("./dummy.pkl")
# ... Other code and operations ...
# Loading the DataFrame and using it
df = pd.read_pickle("./dummy.pkl")
embeddings, ids = df["embedding"].to_numpy(), df["id"]
sim = cosine_sim(embeddings[0], embeddings[1])
# ... Continue with your operations ...
이 코드는 데이터와 임베딩 모델을 사용하여 Pandas DataFrame을 생성하고 저장한 다음, 나중에 필요할 때 불러와 사용하는 예제입니다. 이 코드에서 data는 임베딩을 수행할 데이터를 나타내며, embedding_model은 데이터를 임베딩하는 함수를 나타냅니다. cosine_sim은 임베딩 간 코사인 유사도를 계산하는 함수일 것으로 가정합니다.
DataFrame은 “dummy.pkl” 파일로 저장되며, 필요한 경우 이 파일을 다시 불러와 데이터를 검색하고 원하는 연산을 수행할 수 있습니다.
이것은 빠른 프로토타이핑에는 훌륭하지만 수백만 개의 항목으로 확장하는 데 어떻게 대응할 수 있을까요? 수십억 개의 항목은 어떻게 처리하나요? 메모리에 모든 임베딩을 로드하는 것이 대규모에서 효율적인 방법일까요? 그리고 다중 모달 데이터는 어떻게 처리하나요?
AI 네이티브 벡터DB에 대한 이상적인 해결책은 설정이 간편하며 기존 API와 원활하게 통합되어 빠른 프로토타이핑을 지원하지만 추가 변경 없이 확장할 수 있어야 합니다.
LanceDB는 이러한 접근 방식으로 설계되었습니다. 서버 없이도 설정이 필요하지 않으며 가져와서 사용하기만 하면 됩니다. HDD에 저장되므로 데이터를 전체 메모리에 로드하지 않고도 연산을 실행할 수 있습니다. 또한 Python 및 Javascript 생태계와의 원활한 통합을 지원하여 동일한 코드베이스에서 프로토타입부터 제품 애플리케이션으로 확장할 수 있습니다.
Compute Storage Separation
“컴퓨팅 스토리지 분리”는 시스템에서 컴퓨팅 및 스토리지 리소스를 분리하는 디자인 패턴입니다. 이것은 컴퓨팅 리소스가 스토리지 리소스와 물리적으로 동일한 하드웨어에 위치하지 않음을 의미합니다. 컴퓨팅 스토리지 분리에는 확장성, 성능 및 비용 효율성과 같은 여러 가지 이점이 있습니다.
LanceDB — 내장형 VectorDB
다음은 위의 예제를 LanceDB와 통합하는 방법입니다.
이 코드는 LanceDB를 사용하여 데이터를 저장하고 검색하는 예제입니다. LanceDB는 NoSQL 데이터베이스로 사용자가 특정 엔지니어링 작업 없이 데이터를 저장하고 검색할 수 있는 간단한 인터페이스를 제공합니다.
import lancedb
import numpy as np
import pandas as pd
# Assuming you have already defined your data and embedding_model
data = [...] # Your data
embedding_model = [...] # Your embedding model function
# Connect to LanceDB and create a table
db = lancedb.connect("db")
embeddings = []
ids = []
for i, item in enumerate(data):
embeddings.append(embedding_model(item))
ids.append(i)
df = pd.DataFrame({"id": ids, "embedding": embeddings})
tbl = db.create_table("tbl", data=df)
# ... Other code and operations ...
# Open the table and perform a similarity search
tbl = db.open_table("tbl")
search_embeddings = [embedding_model(new_data)] # Replace with your new data
sim = tbl.search(search_embeddings).metric("cosine").to_pandas()
# ... Continue with your operations ...
이 코드에서 lancedb.connect("db")를 사용하여 LanceDB에 연결하고, db.create_table("tbl", data=df)를 사용하여 테이블을 만들고 데이터를 저장합니다. 나중에 db.open_table("tbl")을 사용하여 테이블을 열고, tbl.search()를 통해 유사성 검색을 수행합니다. 검색할 데이터는 embedding_model(new_data) 함수로 새 데이터를 임베딩하여 사용할 수 있습니다. 검색 결과를 Pandas DataFrame 형태로 가져올 수 있습니다.
이렇게 하면 모든 규모의 벡터 임베딩 워크플로우를 강화할 수 있습니다. LanceDB는 Rust로 구현된 ML 및 LLMs를 위한 현대적인 컬럼형 데이터 형식인 Lance 파일 형식 위에 구축되었습니다.
우리는 Lance 형식을 통한 성능을 대략적으로 측정하는 일부 벤치마크를 만들었습니다. Lance를 사용하면 Parquet 대비 최대 2000배 더 나은 성능을 달성할 수 있습니다. 2000x better performance with Lance over Parquet
Visit about LanceDB or vectordb-recipes and Drop us a 🌟
Reduce Hallucinations from LLM-powered Agents using Long-Term Memory