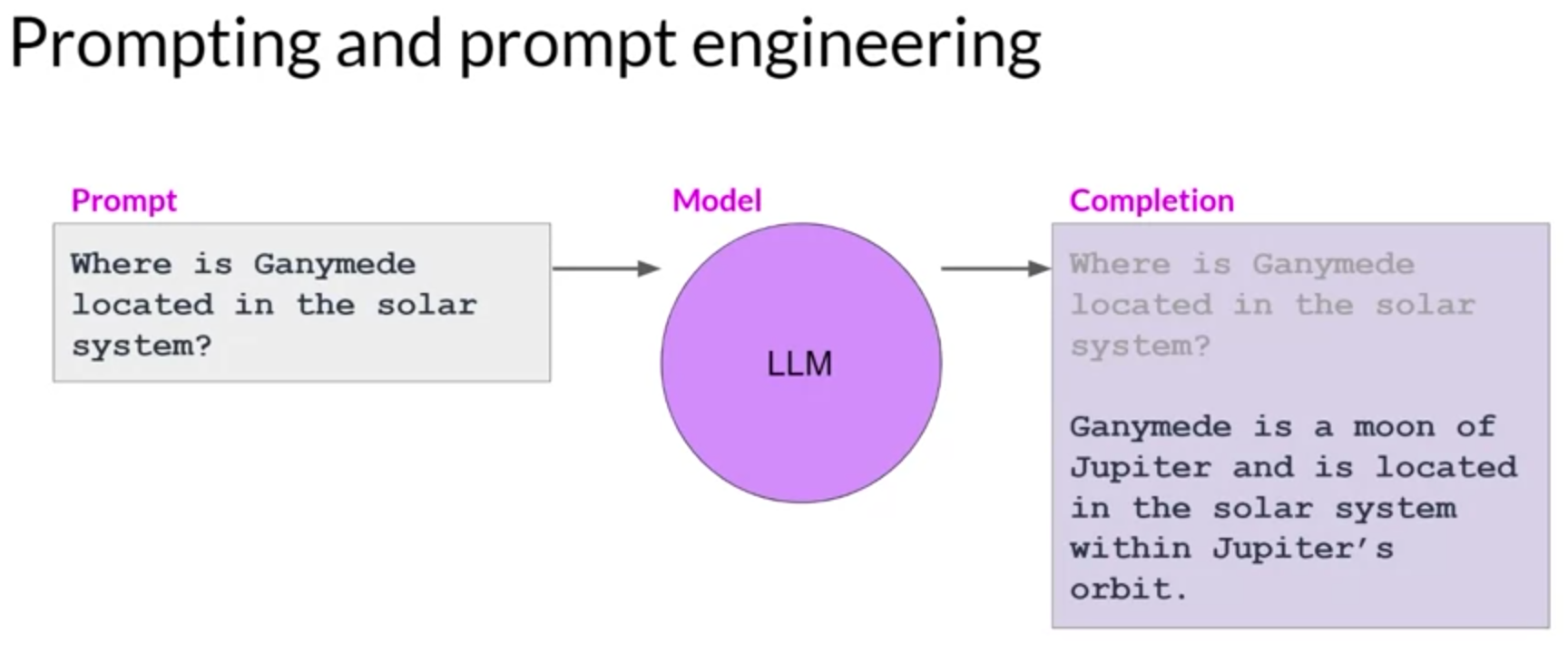
제목: 대화형 언어 모델의 이해와 활용
모델에 입력하는 텍스트를 ‘프롬프트’, 텍스트를 생성하는 것을 ‘추론(inference)’, 출력 텍스트를 ‘완성(completion)’이라 부릅니다. 프롬프트로 사용할 수 있는 텍스트 전체 또는 사용 가능한 메모리는 ‘컨텍스트 윈도우’라고 부릅니다.

이 모델이 뛰어난 성과를 보여주는 예시를 보셨겠지만, 모델이 원하는 결과를 처음에 바로 출력하지 못하는 경우가 종종 있습니다. 프롬프트의 언어나 작성 방식을 여러 번 수정하여 모델이 원하는 방식으로 동작하게 만들어야 할 수 있습니다. 이러한 과정을 ‘프롬프트 엔지니어링’이라고 부릅니다.
프롬프트 엔지니어링은 상당히 광범위한 주제입니다. 하지만 모델이 더 나은 결과를 출력하도록 하는 강력한 전략 중 하나는 프롬프트에 수행하려는 작업의 예시를 포함하는 것입니다. 컨텍스트 윈도우 내에서 예시를 제공하는 것을 ‘컨텍스트 내 학습(in-context learning,ICL)’이라고 부릅니다.
컨텍스트 내 학습을 통해, 프롬프트에 예시나 추가 데이터를 포함함으로써 모델에 작업에 대해 더 많이 배울 수 있습니다. 예를 들어, 리뷰의 감성을 분류하도록 모델에 요청하는 경우, 프롬프트는 지시사항인 “이 리뷰를 분류하라”를 포함하며, 이 경우 리뷰 텍스트 자체가 컨텍스트를 구성합니다. 이러한 방법, 즉 입력 데이터를 프롬프트 내에 포함하는 것을 ‘제로샷 추론(zero shot inference)’이라고 부릅니다.

가장 큰 언어 모델은 이를 놀랍도록 잘 수행하며, 완료해야 하는 작업을 이해하고 좋은 답변을 반환합니다. 하지만 더 작은 모델은 이러한 작업에서 어려움을 겪을 수 있습니다. 예를 들어, GPT-2는 모델이 지시사항을 따르지 않는 것을 볼 수 있습니다. 프롬프트와 일부 연관성 있는 텍스트를 생성하긴 하지만, 모델은 작업의 세부 사항을 파악하지 못하고 감성을 식별하지 못합니다.

이럴 때 프롬프트 내에 예시를 제공함으로써 성능을 향상시킬 수 있습니다. 프롬프트 텍스트가 길어지고, 모델이 수행해야 하는 작업을 보여주는 완성된 예시로 시작합니다. 단일 예시의 포함은 ‘원샷 추론(one shot inference)’이라고 부르며, 이는 이전에 제공한 제로샷 프롬프트와 대비됩니다.

때로는 단일 예시만으로는 모델이 원하는 작업을 배우는데 충분하지 않을 수 있습니다. 그래서 단일 예시를 제공하는 아이디어를 확장하여 여러 예시를 포함하게 됩니다. 이것을 ‘퓨샷 추론(few shot inference)’이라고 합니다.

다시 말해, 예시를 통해 모델이 배우도록 프롬프트를 엔지니어링할 수 있습니다. 가장 큰 모델은 예시가 없는 제로샷 추론에서도 뛰어나지만, 더 작은 모델은 원샷 또는 퓨샷 추론에서 원하는 행동의 예시를 포함하는 것이 유익할 수 있습니다. 하지만 컨텍스트 윈도우를 기억하세요. 모델에 전달할 수 있는 컨텍스트 내 학습의 양에는 한계가 있습니다.

더 큰 모델들이 훈련됨에 따라, 모델이 다양한 작업을 수행하는 능력과 그 작업을 얼마나 잘 수행하는지는 모델의 규모에 크게 의존하는 것이 명확해졌습니다. 반대로, 더 작은 모델들은 일반적으로 훈련된 작업과 유사한 몇 가지 작업에만 능숙합니다.
사용 사례에 적합한 모델을 찾기 위해 몇 가지 모델을 시도해 볼 수도 있습니다. 일단 작동하는 모델을 찾으면, 모델이 생성하는 완성의 구조와 스타일에 영향을 미치는 몇 가지 설정을 실험해 볼 수 있습니다.