과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



Chapter 1: Taking a Case Study Approach
우리의 사례 연구는 고객 생애 주기의 각 단계인 획득, 유지, 참여, 그리고 되찾기를 다룰 것이며, MarTech 부문 내에서 제너레이티브 AI의 네 가지 독특한 응용에 중점을 둘 것입니다. 각 사례 연구에 대해 외부 API와 자체 호스팅된 모델을 사용하여 생성 비용을 추정할 것입니다.
MarTech는 현재 주목받는 분야입니다.
코카콜라의 최근 광고 “Masterpiece”는 필름, 3D, 그리고 Stable Diffusion 기술의 조합을 특징으로 하는 제너레이티브 AI를 일부 사용하여 만들어졌습니다. 이 광고는 뛰어난 실행력을 보였지만, 비용이 저렴하지는 않았습니다! 이는 “pull dimension”을 가져야 했기 때문에 여러 번의 테스트를 거쳤습니다.
MarTech 분야에서는 코카콜라 사례와 같이 “효율성”보다는 “효과성”(소비자에게 호소력 있는 콘텐츠 생성) 측면에서 노력이 평가되는 수많은 예가 있습니다. ChatGPT는 이 기능에 어떻게 영향을 미칠 수 있는지를 보여주는 중요한 영향자로 입증되었습니다.
McKinsey 보고서에 따르면 제너레이티브 AI에 투자하는 기업들은 3%에서 15%의 수익 증가와 10%에서 20%의 매출 ROI 증가를 보고 있습니다.
동시에 AIM 연구에 따르면 기능별로 채택률을 보면 자동차 및 제조업, 소매 및 CPG, 제약 및 헬스케어 분야에서 마케팅에서 제너레이티브 AI의 채택률이 각각 20%, 20%, 17%를 기록하고 있습니다. 마케팅 및 판매는 모든 다른 기능에 비해 가장 높습니다.
이 보고서는 따라서 MarTech 생명주기의 여러 단계에서의 사용 사례를 활용하여 발생하는 비용을 더 잘 문맥화하고 근사치 비용이 어떻게 결정되는지에 대한 이해를 제공할 것입니다.
Exhibit 1: MarTech 생명주기에 걸쳐 Generative AI 솔루션 구현하기

Prompting/Finetuning Technique
- Few-shot learning
- in-context learning
- Adaptive sampling
- temperature tuning
- continuous learning
Adaptive sampling은 모델 학습 및 미세조정에서 사용되는 기술입니다. 기본적으로, 모든 학습 데이터가 동일하게 중요한 것은 아닙니다. 일부 데이터 포인트는 모델에 더 많은 정보를 제공하거나 더 어려울 수 있습니다. Adaptive sampling은 이러한 차이를 인식하고 학습 중에 중요하거나 어려운 샘플에 더 많은 주의를 기울이는 방식으로 작동합니다.
이 방법은 일반적으로 다음과 같은 절차를 따릅니다:
- 데이터셋의 각 샘플에 대한 모델의 예측 오류를 계산합니다.
- 오류가 큰 샘플 (즉, 모델이 잘못 예측하는 샘플)은 더 높은 확률로 선택됩니다.
- 이런 방식으로, 모델은 자주 잘못 예측하는 항목에 더 많은 학습 시간을 보내게 되어 전체적인 성능이 향상됩니다.
Adaptive sampling은 데이터의 불균형을 처리하거나 특정 부분의 데이터에 더 많은 중점을 둘 때 특히 유용합니다. 그러나 이 방식을 사용할 때 주의해야 할 점은, 너무 특정한 오류에 집중하는 것을 피해야 한다는 것입니다. 이렇게 되면 모델이 과적합될 위험이 있습니다.
Continuous learning은 기계 학습에서 중요한 개념으로, 모델이 새로운 데이터에 기반하여 지속적으로 학습하고 개선하는 프로세스를 의미합니다. 전통적인 머신러닝 모델은 학습 데이터 세트에 한 번 학습되고, 그 후에는 업데이트되지 않습니다. 그러나 continuous learning에서는 모델이 새로운 데이터나 정보가 도입될 때마다 지속적으로 업데이트 및 조정됩니다.
이 기법은 특히 데이터가 시간에 따라 변화하는 상황에서 유용합니다. 예를 들면, 사용자의 행동 패턴, 시장 동향, 새로운 제품 또는 서비스 등이 있습니다. Prompting/Finetuning 기법과 함께 사용될 때 continuous learning은 Generative AI 모델이 계속해서 최신 상태를 유지하고, 변화하는 환경에 적응하도록 돕습니다.
Comparing External API and Self-hosted Models
조직의 프로세스에 생성 AI를 배포하는 것은 실제로 두 가지 주요한 방법으로 이루어질 수 있습니다: 외부 API를 사용하거나 Cloud에서 대규모 언어 모델(LLM)을 자체 호스팅하는 것입니다. 이 두 가지 방법 모두 자신만의 장점과 단점이 있으며, 여러분의 선택은 주로 조직의 특정 요구 사항과 제약 조건에 따라 달라질 것입니다.
Exhibit 2 : Comparing External API and Self-hosted Models
External API
외부 API는 API를 통해 접근할 수 있는 사전 구축된 AI 모델을 제공하는 외부 제공자를 의미합니다. 이를 통해 개발자들은 자신의 모델을 훈련하거나 호스팅할 필요 없이 AI 기능을 활용할 수 있습니다.

Self-hosted Models
Cloud에서 언어 모델을 자체 호스팅하는 것은 제3자 API 서비스에 의존하지 않고 자신만의 배포를 원하는 사람들에게 적합한 해결책입니다. 이를 통해 더 많은 통제, 잠재적인 비용 절감, 그리고 아마도 더 나은 성능을 얻을 수 있습니다.

“먼저 가장 중요한 질문은 정량화된 비즈니스 이익을 제공하는 올바른 사용 사례를 식별하는 것입니다. 또한 100%의 정확도를 정말로 추구하는지 고려해야 합니다. 완벽한 정확도를 목표로 한다면, 현재 이 분야가 당신에게 적합하지 않을 수 있습니다.
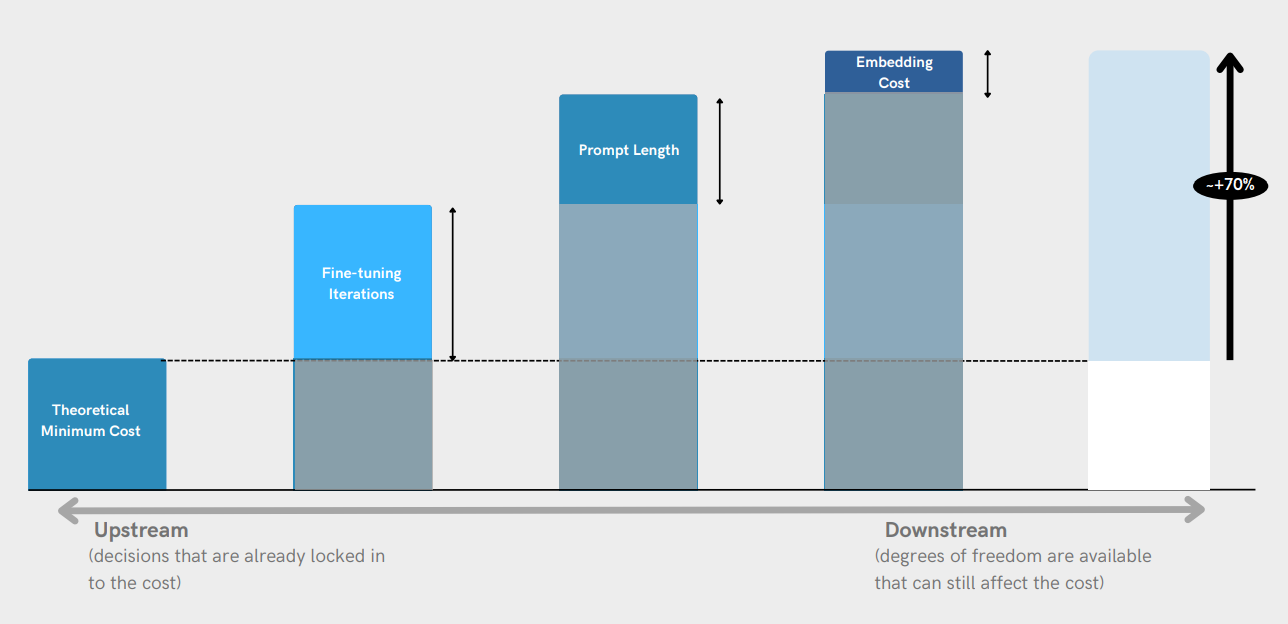
비용 또한 중요한 요소입니다. 개념 증명(POC) 수준에서 작업하든, 클라우드 서비스를 사용하든, API를 활용하든, 비용은 일반적으로 토큰 당으로 계산됩니다. 따라서 주어진 데이터량에 대한 잠재적인 비용에 대해 유익한 추정을 할 수 있습니다.
마지막으로, 검증은 매우 중요합니다. 솔루션이 비즈니스 부서에 이익을 가져다주는지 확대하기 전에 평가하는 것이 중요합니다. 이 접근법은 우리에게 효과적이었습니다.”
Chapter 2 Cost Analysis
비용 분석 섹션은 외부 API 사용 비용과 클라우드 GPU에서의 자체 호스팅 비용을 비교하는 여러 사용 사례로 구성됩니다. 이 섹션에서는 비용 최적화의 잠재적 영역도 탐구할 것입니다.
First Step to Tech Adoption: Calculating RoI
AI를 구현하는 것은 큰 규모나 높은 정확도 요구 사항 때문에 비용이 많이 들 수 있습니다. 그러나 최종적으로는 투자에 대한 긍정적인 수익률(ROI)을 가져와야 합니다. 이는 AI의 효과를 사업 부서와 함께 검증하며, 그것이 상당한 비즈니스 가치를 창출하면 투자할 준비가 되어 있어야 한다는 것을 의미합니다.
MarTech 분야에서 대형 언어 모델 (LLMs)을 배포할 때 중요한 고려사항은 LLMs를 활용함으로써 얻는 ROI(투자 수익률)을 이해하고 정량화하는 것입니다. ROI를 계산하는 것은 LLMs 사용으로 얻는 순수익과 초기 및 지속적인 투자 비용을 비교함으로써 이러한 통합의 재무적 타당성과 성공을 평가하는 데 도움을 줍니다. ROI를 계산하는 공식은 다음과 같습니다:

여기서:
- LLMs로부터의 순수익은 언어 모델의 사용으로 얻는 총 수익을 의미합니다.
- 투자 비용은 LLMs의 배포와 유지 관리와 관련된 초기 설정 비용 및 지속적인 비용을 포함합니다.
이 공식을 활용하여 조직은 생성적 AI에 대한 투자의 효율성을 판단하고 그 전략을 확대, 계속, 또는 변경할지에 대한 정보를 얻을 수 있습니다.

Net Profit from LLM: 이는 LLMs의 사용을 통해 생성된 추가적인 이익을 나타냅니다. 증가된 판매량, 향상된 고객 참여도 및 LLMs에 기인한 기타 수익 창출 결과와 같은 지표를 평가함으로써 결정될 수 있습니다.
이를 통해 LLMs의 사용이 얼마나 효과적으로 회사의 수익을 증가시키는지에 대한 정량적인 평가를 할 수 있습니다.
Total Cost of LLM Implementation: 이는 초기 설정 비용(획득 및 통합과 같은)과 함께 운영 비용(유지 보수 및 인력 교육 포함)을 포함합니다.
이러한 비용들은 LLM을 효과적으로 운영하기 위한 모든 금액을 포함하므로, ROI를 계산할 때 고려해야 할 중요한 요소입니다.
이 공식을 적용함으로써, 조직은 LLMs에 대한 투자의 수익성과 효율성을 시각화할 수 있습니다. 따라서 MarTech 분야에서 정보 기반의 의사 결정 및 전략 최적화를 가능하게 합니다.
현재의 섹션은 LLM 구현의 총 비용에 대한 대략적인 추정치를 제공하고 사용 사례를 기반으로 탐구할 수 있는 옵션을 제시하는 것을 목표로 합니다.
Using External APIs
Use Case 1 – Customer Complaint Redressal in the Automotive Industry 자동차 산업에서의 고객 불만 처리
이러한 사용 사례의 경우 몇 가지 이유로 AI 모델을 미세 조정하는 것이 중요합니다: 산업 특정 용어, 독특한 자동차 맥락, 잠재적인 오해와 관련된 중요한 안전 영향. 미세 조정은 AI 모델이 정확하고 맥락에 맞는 응답을 제공하고, 수동 감독을 최소화하며, 맞춤형 고객 경험을 제공함으로써 경쟁 우위를 제공하는 데 도움을 줍니다.
이러한 사용 사례에 대한 총 비용을 추정하는 방법은 다음과 같습니다:
단계 1: 모델을 미세 조정하기 위한 지시 세트 토큰의 수를 계산합니다.
이 단계에서는 자동차 산업의 고객 불만 사항에 특화된 지침을 LLM에 제공하기 위해 필요한 토큰의 수를 계산합니다. 토큰은 단어, 숫자, 구두점 등의 조합으로 이루어진 단위로, 모델의 처리 능력을 결정하는 데 사용됩니다. 지침 세트는 특정 산업과 관련된 용어와 맥락을 모델에 알려줍니다.
고객 불만에 관한 데이터 세트의 크기를 예상하고 이를 기반으로 미세 조정에 필요한 토큰의 수를 계산하였습니다. 계산 방식은 다음과 같습니다:
- 훈련 데이터 세트의 고객 불만 수를 약 6백만으로 가정합니다. 각 불만당 10개의 문장이 있고, 각 문장당 평균 7개의 토큰이 있다고 가정하면, 총 토큰 수는 4억 2천만 토큰입니다.
- 전체 텍스트 볼륨 중 도메인 특화 코퍼스가 차지하는 비율을 20%로 가정합니다. 따라서 도메인 특화 코퍼스 크기는 4억 2천만 토큰의 20%인 8천 4백만 토큰입니다.
- 지침 세트 토큰은 도메인 특화 코퍼스 크기에 비례하며 코퍼스의 50%를 차지한다고 가정합니다. 따라서 지침 세트 토큰의 수는 8천 4백만 토큰의 50%인 4천 2백만 토큰입니다.
이러한 계산을 통해 미세 조정에 필요한 토큰의 수를 정확하게 예측할 수 있습니다.
특화된 코퍼스의 크기가 클수록, AI 모델은 해당 분야의 질의응답에 더욱 효과적으로 반응할 수 있습니다. 특정한 문맥이나 전문 용어를 더 정확하게 파악하고 처리할 수 있게 되기 때문입니다. 그러나 일반적인 사용 사례의 경우, 전체 코퍼스에 대해 미세 조정을 진행하게 될 것입니다. 이는 모델이 다양한 문맥과 시나리오에 더욱 유연하게 대응할 수 있도록 하기 위함입니다.
단계 2: 추론(inference) 단계에서 토큰 계산
추론(inference) 단계에서는 모델이 새로운 데이터나 질문에 대한 응답을 생성합니다. 이 단계에서 소비되는 토큰 수를 계산하는 것은 비용 추정의 중요한 부분입니다.
- 평균 응답 길이 예측: 먼저, 모델이 어떤 유형의 질문에 대해 얼마나 많은 토큰을 생성할 것인지 예상해야 합니다. 예를 들어, 고객의 불만 사항에 대한 답변은 50 토큰으로 구성될 수 있습니다.
- 일일/월간 질의응답 횟수 예측: 다음으로, 하루 혹은 한 달 동안 시스템에 얼마나 많은 질문이 제출될 것으로 예상되는지 추정합니다. 예를 들면, 하루에 1,000개의 질문이 제출될 수 있습니다.
- 총 토큰 수 계산: 예상 응답 길이와 일일 질의응답 횟수를 곱하여 하루 동안 생성될 토큰 수를 계산합니다. 위의 예시를 사용하면, (50 \text{ 토큰/응답} \times 1,000 \text{ 응답/일} = 50,000 \text{ 토큰/일}).
이러한 계산을 통해 추론 단계에서 발생할 토큰 수를 알 수 있으며, 이를 바탕으로 연관된 비용을 추정할 수 있습니다.
Step – 2: Calculate the number of tokens generated for Inference
3%의 차량 소유자(150,000명)가 매월 챗봇과 상호 작용하고 각 상호 작용마다 평균적으로 1200 토큰(입력 및 출력)이 소비된다고 가정했습니다. 따라서 이는 총 토큰 수를 약 150,000 * 1200 = 180백만 토큰으로 계산할 수 있습니다. 이 계산을 통해 한 달 동안 챗봇을 통해 생성되는 토큰의 대략적인 수를 알 수 있으며, 이를 바탕으로 관련 비용을 추정할 수 있습니다.
이 비용은 반복적이며, 사용량에 따라 기업이 매월 부담해야 합니다. 따라서 예측 가능한 사용 패턴을 갖는 조직은 이러한 비용을 예산에 포함하여 장기적인 투자 계획을 세울 수 있습니다.
단계 3 미세조정과 추론의 예상 비용 계산
아래에서 AI 구현의 예상 비용을 계산하는 방법에 대해 설명하겠습니다:
- Fine-tuning 비용:
- 클라우드 공급자나 API 서비스에 따라 특정 데이터나 토큰에 기반한 모델 튜닝 또는 학습에 연관된 비용이 있습니다. 이전에 계산한 42백만 토큰의 튜닝 비용을 토큰당 학습 비용과 곱합니다. 예: 토큰당 튜닝 비용이 $0.0001인 경우:
Fine-tuning 비용 = 42백만 토큰 x $0.0001/토큰 = $4,200
- 추론 비용:
- 튜닝과 마찬가지로 추론 중에 생성되는 모든 토큰에 연관된 비용이 있습니다. 이전에 계산한 180백만 토큰의 추론을 토큰당 추론 비용과 곱합니다. 예: 토큰당 추론 비용이 $0.00001인 경우:
추론 비용 = 180백만 토큰 x $0.00001/토큰 = $1,800
- 총 비용:
- 위의 두 단계에서 나온 비용을 더하여 그 달의 총 예상 비용을 얻습니다. 총 비용 = Fine-tuning 비용 + 추론 비용
총 비용 = $4,200 + $1,800 = $6,000
이 비용들은 설명을 위한 것이며, 실제 요금은 공급자에 따라 다를 수 있습니다. 데이터 저장, 유지 관리 또는 추가 자원과 같은 기타 고정 비용도 발생할 수 있습니다. 그러나 이 기본 계산은 MarTech 생애 주기에서 AI 구현을 계획하고 예산을 세우기 위한 기본을 제공합니다.
Step 3 Calculate the expected cost of Fine-tuning and Inference


- babbage-002와 davinci-002는 원래의 GPT-3 기본 모델을 대체하기 위한 것들로, 감독하에 미세조정(fine-tuning)을 통해 훈련되었습니다.
- 한편, GPT-3.5 Turbo는 RLHF(Reinforcement Learning from Human Feedback)의 통합으로 인해 가장 추천되는 선택입니다.
RLHF는 모델을 향상시키기 위해 인간의 피드백을 기반으로 강화 학습을 사용하는 방법을 나타냅니다. 이는 모델이 실제 사용자와의 상호 작용에서 발생할 수 있는 시나리오에 더 잘 대응하도록 만듭니다.
Use Case 2 – Sentiment Analysis for an eCommerce Company
API의 기능 호출을 활용하면, 사용자는 외부 데이터베이스로부터 프롬프트 내의 조직적인 데이터를 추출할 수 있습니다. 이 방법은 비용을 절감하고 여러 방면에서 활용할 수 있을 뿐만 아니라, 사용자의 쿼리에 대해 실시간으로 맞춤화된 응답을 제공할 수 있습니다.
이때, 사용된 함수들은 모델의 컨텍스트 제한 안에서 입력 토큰으로 계산됩니다.
외부 API를 사용하여:
단계 1: 입력 및 출력 토큰의 수를 계산합니다.
매달 기반으로 사용량에 따라 이 비용은 반복적이며 조직이 부담해야 합니다.
- 모델에게 하루에 대략 1000개의 쿼리가 요청된다고 가정하면 (한 달에 30000개), 입력 쿼리당 평균 약 150 토큰, 출력 쿼리당 평균 약 500 토큰으로 계산됩니다. 이렇게 계산하면 총 500만 개의 입력 토큰과 1600만 개의 출력 토큰이 됩니다.
- 각 프롬프트가 추가로 150개의 입력 토큰에 대한 함수 호출을 포함한다고 가정하면, 총 수는 1000만 개의 입력 토큰이 됩니다.
다시 설명드리면, 일일 쿼리 수는 1000개로, 이는 한 달에 30000개의 쿼리에 해당합니다. 입력 쿼리 당 150 토큰과 출력 쿼리 당 500 토큰을 고려하면, 입력 토큰의 총 수는 4,500,000 (150 토큰 x 30000 쿼리)이고, 출력 토큰의 총 수는 15,000,000 (500 토큰 x 30000 쿼리)입니다.
만약 각 프롬프트가 추가적인 150개의 입력 토큰에 대한 함수 호출을 포함한다면, 이는 한 달에 4,500,000 토큰 (150 토큰 x 30000 쿼리)에 해당하게 됩니다.
따라서 총 입력 토큰의 수는 기존의 4,500,000 토큰에 함수 호출로 인한 4,500,000 토큰을 더해 9,000,000 토큰이 됩니다.
제가 앞서 10백만으로 잘못 언급한 부분을 정정합니다. 올바른 총 입력 토큰 수는 9백만 토큰입니다.
단계 2 – 추론의 예상 비용 계산
추론의 비용은 주로 사용한 토큰 수와 사용한 AI 모델의 비용에 따라 달라집니다. 따라서 이 비용을 계산하기 위해서는 다음의 단계를 따라야 합니다:
- 토큰의 총 수 결정: 앞서 설명한 것처럼 한 달 동안 총 9백만 개의 입력 토큰과 15백만 개의 출력 토큰이 예상됩니다. 따라서 총 토큰 수는 24백만 토큰입니다.
- 모델별 토큰 비용 파악: 사용하려는 AI 모델에 따라 토큰당 비용이 정해져 있습니다. 예를 들어, GPT-3.5 Turbo의 토큰당 비용이 $0.01이라고 가정하면: ( 토큰당 비용 \times 총 토큰 수 ) ( $0.01 \times 24,000,000 = $240,000 ) 따라서 GPT-3.5 Turbo를 사용할 경우 한 달 동안의 추론 비용은 약 $240,000입니다.
- 추가 비용 고려: AI 서비스 제공업체에 따라 추가적인 비용(예: API 호출 비용, 데이터 전송 비용 등)이 발생할 수 있으므로 이를 고려해야 합니다.
이렇게 계산된 추론의 총 비용을 통해 조직은 자신들의 예산과 비교하여 AI를 효과적으로 활용할 수 있는지 판단할 수 있습니다.

Optimizing Cost Using Embedding Models
임베딩 모델을 사용하여 비용을 최적화하면 대량의 데이터를 처리할 때 비용 효율적인 방법을 제공합니다. 비용은 다음과 같이 나눌 수 있습니다:
- 임베딩 생성:
- 사전 훈련된 모델을 사용하여 각 문서에 대한 임베딩을 생성합니다. 여기서의 비용은 처리하는 토큰의 수와 사용하는 특정 모델에 따라 다릅니다.
- 1000 토큰당 $0.02로 가정하면, 84백만 토큰의 임베딩 생성 비용은 (84,000 (천 토큰) \times $0.02 = $1,680)가 됩니다.
- 저장 비용:
- 임베딩이 생성되면 저장해야 합니다. 이러한 벡터는 일반적으로 원래 문서에 비해 크기가 작습니다. 그러나 이러한 임베딩을 다룰 수 있는 데이터베이스(벡터 데이터베이스 같은)는 자체 비용이 있습니다.
- 84백만 토큰의 도메인 특화 코퍼스의 경우, 1000개의 임베딩당 $0.01의 저장 비용을 가정하면 50k 문서의 저장 비용은 (50 \times $0.01 = $0.50)이 됩니다.
- 쿼리 및 분석 비용:
- 임베딩이 저장된 후에는 유사성 쿼리나 다른 유형의 분석을 실행할 수 있습니다. 여기서의 비용은 쿼리의 빈도와 분석의 복잡성에 따라 다릅니다.
- 쿼리당 $0.001이라고 가정하고 한 달에 10,000개의 쿼리를 실행한다면, 이는 (10,000 \times $0.001 = $10)의 비용이 발생합니다.
합계:
$1,680 (임베딩 생성) + $0.50 (저장) + $10 (쿼리) = $1,690.50로 84백만 토큰의 도메인 특화 코퍼스를 사용할 때의 예상 월별 비용입니다.
참고: 이러한 숫자들은 설명을 위한 것이며, 제공업체, 사용 사례의 구체적인 내용 및 기타 변수에 따라 다를 수 있습니다.

임베딩 모델을 사용할 때 벡터 데이터베이스의 비용이 전체 비용의 대부분을 차지합니다. 벡터 데이터베이스는 임베딩된 벡터들을 효과적으로 저장, 검색, 및 조작하기 위해 설계된 특별한 데이터베이스입니다. 이러한 데이터베이스는 대량의 임베딩 데이터를 처리하고, 빠른 검색을 위한 최적화된 쿼리 메커니즘이 필요하기 때문에 일반적인 데이터베이스와 비교하여 높은 비용이 들 수 있습니다.
이러한 벡터 데이터베이스의 주요 기능은 다음과 같습니다:
- 빠른 유사성 검색: 사용자는 특정 벡터에 가장 가까운 벡터를 빠르게 찾을 수 있어야 합니다. 이는 추천 시스템, 클러스터링, 다른 많은 응용 프로그램에서 중요합니다.
- 대량의 벡터 저장: 임베딩은 수백만 개, 혹은 그 이상의 토큰에 대한 정보를 포함할 수 있기 때문에, 데이터베이스는 이런 대량의 데이터를 효과적으로 처리하고 저장할 수 있어야 합니다.
- 확장성: 사용자의 데이터 및 쿼리 요구가 증가함에 따라 데이터베이스는 확장 가능해야 합니다.
- 안정성 및 내구성: 중요한 데이터를 저장하기 때문에 데이터의 손실이나 손상 없이 안정적으로 운영되어야 합니다.
이러한 기능과 요구 사항들 때문에 벡터 데이터베이스의 구축 및 유지 보수는 복잡하며, 따라서 비용이 높을 수 있습니다. 그러나 임베딩 모델을 효과적으로 활용하기 위해서는 이러한 데이터베이스가 필수적입니다.