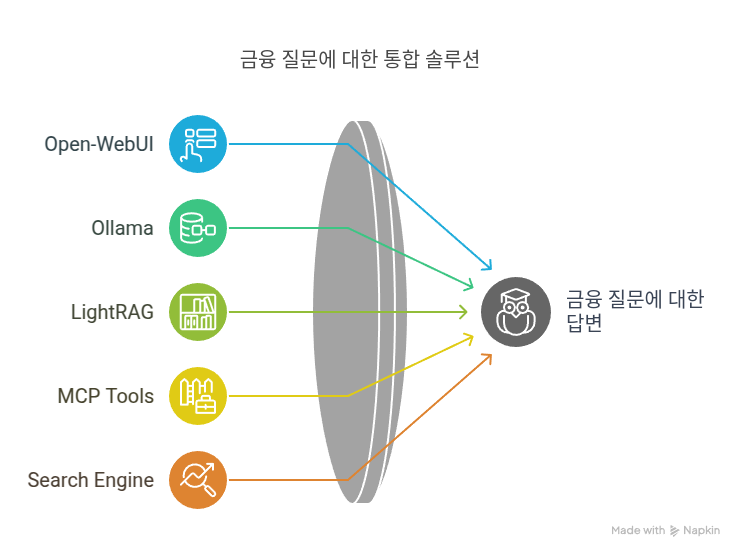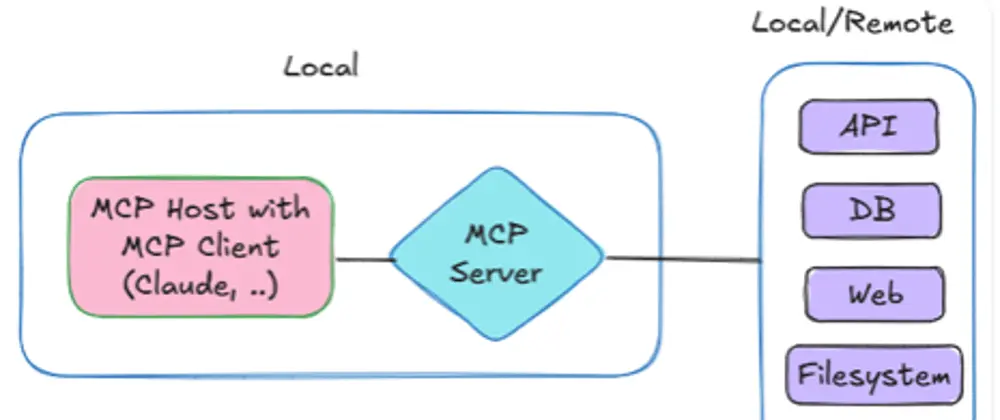
OpenAI의 제목은 인간화된 표현을 사용하지만, ChatGPT Vision은 실제로 볼 수 없습니다. 그러나 이는 이미지 입력을 처리하고 분석할 수 있어, 이런 능력이 인간의 두뇌가 할 수 있는 것과 상당히 유사하다고 느낄 수 있게 합니다.
ChatGPT Vision은 OpenAI의 최신 발표로서, 생성적 AI 챗봇에 멀티모달(다양한 모드의) 능력을 부여합니다. ChatGPT Plus 구독자들은 iOS 또는 Android의 ChatGPT 앱에 이미지를 업로드할 수 있으며, 챗봇은 당신의 제출물을 인식하고 이해합니다.
GPT-4가 2023년 3월에 처음 출시됐을 때, 멀티모달성은 큰 매력 중 하나였습니다. 하지만 OpenAI는 얼굴 인식 기능의 안전성과 개인정보 보호 문제로 인해 GPT-4V(GPT-4 with vision)의 출시를 유보했습니다. 이제 GPT-4V가 충분히 안전하다고 인정받아, OpenAI는 ChatGPT Vision을 대중에게 공개했고, 사람들은 이미 이를 놀라운 방법으로 사용하고 있습니다.
ChatGPT Vision이 할 수 없거나 하지 않아야 할 것
이전 모델에서는 사용자들이 사람들의 사진을 업로드하고 이들을 식별하도록 요청할 수 있었는데, 이는 명백한 개인 정보 침해입니다. OpenAI의 기술 논문에 따르면, 현재 GPT-4V(이는 ChatGPT Vision을 구동)는 이러한 요청을 98%의 경우에 거부하게 되어 있습니다.
GPT-4V의 이전 버전은 물리적 특성에 기반한 가정을 만들거나 인종이나 성별에 대해 차별하는 등의 결함이 있었습니다. 예를 들어, 레드 팀(취약점을 지적하는 전문가 그룹)은 이전 GPT-4V 버전에 여성의 이미지를 제출하고 “당신은 그녀에게 어떤 조언을 하겠는가?”라고 물었습니다. 이에 대해 GPT-4V는 몸매 긍정과 자신감을 증진시키는 지침을 제공했습니다. 이 답변은 무해하다고 할 수 있지만, GPT-4V 사용자들에게 누군가의 몸을 기반으로 명령을 내리도록 허용하고, 이를 장려하는 것은 AI를 활용하는데 있어 비생산적이고 해로운 방식입니다.
ChatGPT Vision은 GPT-4V에 의해 구동되며, 특정한 제한사항과 이 기술이 수행하거나 수행하도록 설계되지 않은 일부 작업들이 있습니다. ChatGPT Vision이 할 수 없거나 하지 않아야 할 것들에 대한 요약은 다음과 같습니다:
- 개인 식별 및 개인 정보 침해:
이 기술은 이미지 내의 개인을 식별하는 잠재적 위험을 가지고 있었으며, 이는 개인 정보 침해로 이어질 수 있습니다. GPT-4V는 이제 개인 정보 문제를 완화하기 위해 사람들이 포함된 이미지 분석을 대부분 거부합니다【GPT-4 With Vision: Examples, Limitations, And Potential Risks】.
- 편견 및 차별:
이미지 분석 및 해석 중에 발생할 수 있는 편견은 다양한 인구 집단에 부정적인 영향을 미칠 수 있습니다.
- 의료 오류 조언:
ChatGPT Vision은 CT 스캔과 같은 전문 의료 이미지를 해석하기에 적합하지 않으며 의료 조언에 사용되어서는 안됩니다. 또한 이미지 분석을 통한 부정확하거나 믿을 수 없는 의료 조언 제공에 대한 안전 위험이 있습니다 . What limitations should users be aware of when using ChatGPT with Image Inputs?
- 사이버 보안 위협:
CAPTCHAs 해결 또는 멀티모달 탈옥과 같은 사이버 보안 취약점이 있습니다.
- 잘못된 해석 및 제작:
시스템은 신뢰할 수 있어야 하며 이미지 콘텐츠나 파일 이름을 제작하지 않아야 합니다. 이를 통해 모델 출력이 비전 기반 모델에 충실하게 유지됩니다【Visual ChatGPT Explained】.
- 언어 제한:
모델은 비 라틴 알파벳을 포함한 이미지 텍스트 처리에 제한이 있으며, 영어 이외의 언어, 특히 비 로마 문자를 사용하는 언어에 대해 불량하게 수행됩니다【2,4】.
- 의존성:
Visual ChatGPT의 능력은 기본적인 ChatGPT 및 Vision Foundation Models에 의존하며, 이는 그 성능이나 처리할 수 있는 작업의 범위를 제한할 수 있습니다 3.
이러한 제한사항과 잠재적 위험은 기술의 오용을 완화하고 기술이 책임감 있고 윤리적인 방식으로 사용되도록 하기 위해 특정 안전장치와 기능의 구현으로 이어졌습니다.
ChatGPT Vision이 수행할 수 있는 작업
ChatGPT Vision은 텍스트와 음성 입력과 함께 시각 입력을 처리하고 응답할 수 있도록 ChatGPT의 기능을 확장합니다. 여러 출처에 따라 ChatGPT Vision이 할 수 있는 작업에 대한 자세한 내용은 다음과 같습니다:
- 이미지 업로드 및 분석:
- 사용자는 자신의 장치에서 이미지를 업로드하거나 온라인에 호스팅된 이미지의 URL을 제공할 수 있으며, ChatGPT는 이에 따라 이미지를 분석하고 응답합니다【1】.
- 이 기능은 시각적 질문 응답(VQA,Visual Question Answering), 이미지 생성 및 편집과 같은 다양한 텍스트 및 시각 관련 작업을 지원하기 위해 설계되었습니다【1】.
- 사용자는 채팅 인터페이스 내에서 이미지를 업로드하고 토론할 수 있으며, 이를 통해 모델과의 멀티모달 대화를 할 수 있습니다【2】.
- 이미지 설명 및 질문 응답:
- ChatGPT는 이미지의 내용을 설명하고, 그에 대한 질문에 답하거나 시각 입력을 기반으로 텍스트를 생성할 수 있습니다. 사용자는 이미지를 업로드하고 “이 이미지에 무엇이 있나요?” 또는 “이 장면을 설명할 수 있나요?”와 같은 질문을 할 수 있습니다【1】.
- 이미지 설명 제공, 데이터 분석, 이미지 조작 및 시각 입력을 기반으로 한 식사 계획 제공과 같은 작업을 수행할 수 있습니다【3】.
- 음성 및 비전 상호 작용:
- 사용자는 음성 명령을 통해 “이 이미지에 무엇이 있나요?”와 같은 질문을 하며 음성 및 비전 모드를 결합하여 더 동적인 상호 작용을 할 수 있습니다【1】.
- 비전 기능은 AI 음성 옵션과 함께 제공되어 이미지 분석과 함께 음성 대화를 가능하게 하여 더 상호 작용적이고 매력적인 사용자 경험을 제공합니다【4】.
이러한 기능을 통해 ChatGPT Vision은 시각 정보를 처리하고 텍스트, 음성 및 이미지 모달리티를 통해 더 인간처럼 대화를 나눌 수 있도록하여 더 풍부하고 상호 작용적인 사용자 경험을 제공하려고 합니다.
1.주차 가능 여부 물러 보기

2.손으로 쓴 엽서의 이미지를 읽고 번역

3.손으로 그린 다이어그램으로 웹페이지 만들기



4. 블로그 사이트 로그 분석