LLAMA-2와 같은 오픈 소스 모델을 사용하여 YouTube 동영상 관련 질문을 처리하는 챗봇 개발합니다.
미리 학습된 LLM은 유용하지만, 연속적인 학습 기능이 없어서 때로는 부정확한 정보(환상,hallucinations)를 제공할 수 있다는 한계가 있습니다. 이 문제를 해결하기 위해 질문 프롬프트에 상황 정보를 포함시키는 방법이 중요합니다. 이렇게 하면 오픈 소스 모델을 효과적으로 활용하면서 동시에 사용자의 개별적이거나 전용 데이터 소스와 함께 사용할 수 있게 됩니다.
또한 LLM에 사용자의 데이터를 추가하는 것은 다양한 데이터 형식과 그 데이터가 여러 저장소에 흩어져 있을 수 있다는 점 때문에 어려움이 있습니다. 예를 들어 JSON, 비디오, 오디오, PDF 등과 이러한 데이터 소스가 Elasticsearch나 SQL 데이터베이스와 같은 여러 저장소에 흩어져 있을 수 있기 때문입니다. 이러한 문제를 해결하기 위해 Llamaindex를 사용하면 다양한 데이터 소스를 챗봇의 지식베이스에 통합하는 작업을 간소화해줍니다.
애플리케이션 설계
QA Bot을 구현하기 위해서는 주로 두 가지 주요 단계가 포함됩니다:
1.동영상 색인화
이 단계에서는 URL로부터 YouTube 동영상을 다운로드하고, 오디오 텍스트를 추출한 후 내용을 VectorStore에 색인화해야 합니다. 이번 애플리케이션에서는 색인을 저장소에 기록하지 않고, 대신 쿼리 목적으로 메모리에 보관하고 있습니다.
설명:
- 이 설계에서는 YouTube 동영상의 URL을 통해 동영상을 다운로드합니다.
- 동영상에서 오디오 텍스트를 추출합니다.
- 이렇게 추출된 오디오 텍스트는 VectorStore라는 시스템에 색인화됩니다.
- 별도의 저장소에 색인을 저장하지 않고, 애플리케이션은 쿼리를 위해 그 색인을 메모리에 직접 보관합니다.

2.쿼리
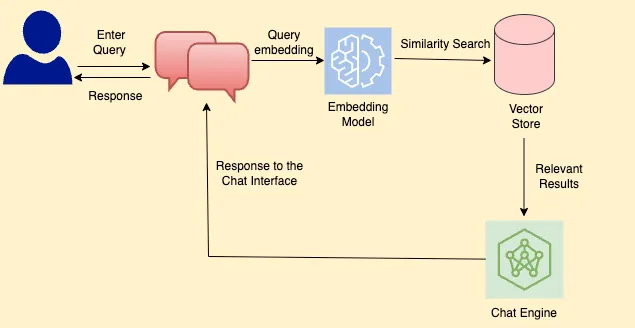
데이터가 색인화된 후에는 LLM이 동영상에서 관련 정보를 검색하고 사용자에게 답변할 수 있어야 합니다. 이 단계는 LLM이 지식 베이스에 없는 정보에 접근할 수 있게 해줍니다.
설명:
- 색인화된 데이터를 통해 LLM은 사용자의 질문에 맞는 동영상의 관련 정보를 찾아서 응답합니다.
- 이 기능은 LLM이 원래 가지고 있지 않은, 즉 그들의 기본 지식 베이스에 포함되지 않은 정보에도 접근할 수 있도록 해줍니다.

이 그림은 챗봇의 쿼리 처리 메커니즘을 설명하는 플로우차트입니다.

전체를 요약하면, 다음 기능을 가진 streamlit 앱을 만듭니다.
- 사용자로부터 입력받은 YouTube URL 처리:
- 사용자로부터 YouTube URL을 입력받고, 해당 동영상의 트랜스크립트를 벡터 저장소의 문서로 색인화합니다.
- 챗 인터페이스:
- 사용자가 동영상에 관한 질문을 할 수 있는 인터페이스를 제공합니다.
- LLM의 지식 확장:
- 벡터 저장소에서 검색된 정보를 이용하여 LLM (LLAMA 2)의 지식을 확장합니다. 따라서 모델은 LlamaIndex의 챗 엔진을 사용하여 동영상을 기반으로 관련된 응답을 제공합니다.
- 채팅 기록 저장 및 업데이트:
- 앱은 채팅 기록을 저장하고 업데이트해야 합니다.
- 세션별 벡터 저장소 유지:
- 앱은 주어진 세션에 대해 메모리 내의 벡터 저장소를 유지해야 합니다.
이 앱은 YouTube 동영상의 내용을 기반으로 사용자의 질문에 응답하는 챗봇 기능을 제공하며, 사용자 세션 동안의 질문 및 응답 기록과 벡터 데이터를 메모리에서 관리합니다.

해당 메시지는 프로그램이 필요로 하는 메모리를 할당받지 못했을 때 발생하는 메시지입니다. 여기서는 약 13.2 GB의 메모리가 필요로 하지만, 메모리 잠금 (mlock)에 실패했습니다.
mlock은 특정 프로세스가 사용하는 메모리 영역을 스왑되지 않게 하는 데 사용되는 시스템 호출입니다. 일반적으로 일부 라이브러리나 애플리케이션은 메모리가 물리 RAM에 항상 올라가 있도록 보장하기 위해 이를 사용합니다.
RLIMIT_MLOCK은 프로세스가 mlock을 사용하여 잠글 수 있는 메모리의 최대 크기를 설정하는 리눅스 시스템 제한입니다.
llm_load_tensors: LLM 모델 텐서를 로드하는 과정에서 필요한 메모리가 약 13189.98 MB (약 13.2 GB)임을 나타냅니다.warning: failed to mlock 75202560-byte buffer: 메모리 잠금 (mlock)에 실패했음을 알리는 경고 메시지입니다. 이는 주어진 버퍼 크기 (약 75.2 MB)의 메모리를 잠그려고 시도했지만, 이미 1970790400 bytes (약 1.9 GB)의 메모리가 잠겨 있기 때문에 추가 메모리를 할당할 수 없었다는 것을 의미합니다.Try increasing RLIMIT_MLOCK: 이 메시지는 메모리 잠금 제한 (RLIMIT_MLOCK)을 늘려보라는 조언입니다. 이 제한을 높이면 더 많은 메모리를 잠글 수 있게 됩니다.