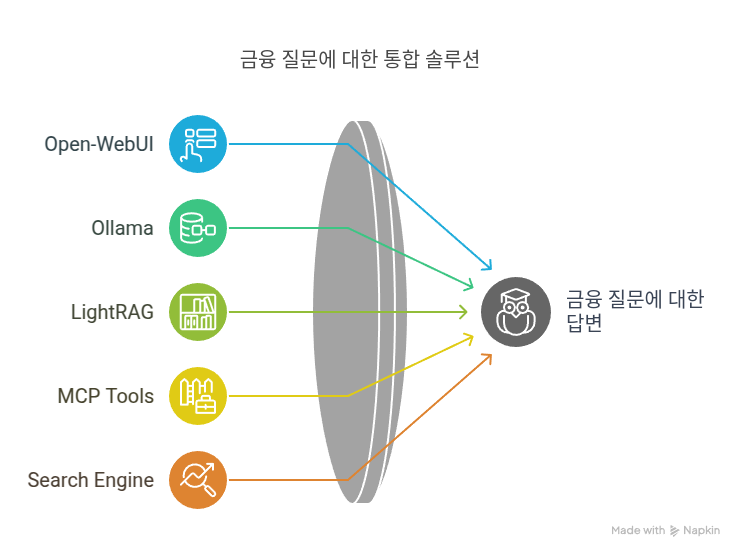
과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



LlamaIndex High-Level Concepts
대규모 언어 모델(LLM)은 현대의 인공 지능 기술에서 중요한 역할을 담당하며, 사용자의 쿼리에 대한 정확하고 유익한 응답을 생성하는 데 효과적입니다. 그러나 이러한 모델은 종종 사용자 정의 데이터를 활용하여 성능을 향상시키는 데 어려움을 겪을 수 있습니다. 이 문제를 해결하기 위해 LlamaIndex는 사용자 정의 데이터를 취득, 구조화 및 접근할 수 있는 통합 데이터 프레임워크를 제공하며, 이를 통해 사용자는 LLM 기반의 응용 프로그램을 쉽게 구축하고 향상시킬 수 있습니다. 이 문서에서는 LlamaIndex의 고수준 개념, 주요 구성 요소 및 파이프라인 구축에 필요한 다양한 도구와 모듈에 대해 탐구합니다. LlamaIndex를 통해 사용자는 자신만의 검색 증강 생성(RAG) 파이프라인을 구성하고, Q&A, 챗봇, 에이전트와 같은 다양한 LLM 기반 응용 프로그램을 개발할 수 있습니다.
팁: 아직 하지 않았다면, 이 글을 읽기 전에 설치하고 기본 튜토리얼을 완료하세요. 이렇게 하면 훨씬 더 이해하기 쉬워질 것입니다!
LlamaIndex는 사용자 정의 데이터를 기반으로 LLM(대규모 언어 모델) 기반 응용 프로그램(예: Q&A, 챗봇, 에이전트)을 구축하는 데 도움을 줍니다.
이 고수준 개념 가이드에서는 다음을 배울 수 있습니다:
- 사용자 정의 데이터와 LLM을 결합하기 위한 검색 증강 생성(Retrieval Augmented Generation, RAG) 패러다임
- LlamaIndex의 주요 개념 및 모듈로 자체 RAG 파이프라인을 구성하기.
검색 증강 생성 (Retrieval Augmented Generation, RAG)
검색 증강 생성(RAG)은 사용자 정의 데이터로 LLM을 향상시키기 위한 패러다임입니다. 일반적으로 두 단계로 구성됩니다:
- 색인 생성 단계(indexing stage): 지식 기반을 준비하고,
- 쿼리 단계(querying stage): 지식에서 관련 컨텍스트를 검색하여 LLM이 질문에 응답하는 데 도움을 주는 단계입니다.

LlamaIndex는 이 두 단계를 매우 쉽게 만들어주는 필수 툴킷을 제공합니다. 각 단계를 자세히 살펴봅시다.
색인 생성 단계
LlamaIndex는 일련의 데이터 커넥터와 인덱스를 통해 지식 기반을 준비하는 데 도움을 줍니다.

데이터 커넥터: 데이터 커넥터(즉, 리더)는 다양한 데이터 소스와 데이터 포맷에서 데이터를 가져와 간단한 문서(Document) 표현(텍스트와 간단한 메타데이터)으로 변환합니다.
문서 / 노드: 문서는 어떠한 데이터 소스에 대한 일반적인 컨테이너로, 예를 들어 PDF, API 출력 또는 데이터베이스에서 검색한 데이터가 될 수 있습니다. 노드는 LlamaIndex에서의 데이터의 원자 단위이며 소스 문서의 “chunk”을 나타냅니다. 이는 메타데이터와 관계(다른 노드에 대한)를 포함하여 정확하고 표현력 있는 검색 작업을 가능하게 하는 풍부한 표현입니다.
데이터 인덱스: 데이터를 취득하면, LlamaIndex는 데이터를 쉽게 검색할 수 있는 형식으로 인덱싱하는 데 도움을 줍니다. 내부적으로, LlamaIndex는 원시 문서를 중간 표현으로 파싱하고, 벡터 임베딩을 계산하며, 메타데이터를 유추합니다. 가장 일반적으로 사용되는 인덱스는 VectorStoreIndex입니다.
쿼리 단계
쿼리 단계에서는 RAG 파이프라인이 사용자 쿼리를 기반으로 가장 관련성 있는 컨텍스트를 검색하고, 그것을 LLM(그리고 쿼리와 함께)에 전달하여 응답을 생성합니다. 이로 인해 LLM은 원래의 훈련 데이터에는 없는 최신의 지식을 얻게 되며(또한 환영을 줄입니다). 쿼리 단계에서의 주요 도전은 (잠재적으로 많은) 지식 기반 위에서의 검색, 조정, 및 추론입니다.
LlamaIndex는 Q&A(쿼리 엔진), 챗봇(채팅 엔진) 또는 에이전트의 일부로서 RAG 파이프라인을 구축하고 통합하는 데 도움이 되는 구성 가능한 모듈을 제공합니다. 이러한 구성 요소는 랭킹 선호도를 반영하도록 사용자 지정할 수 있으며, 구조화된 방식으로 여러 지식 기반에 대해 추론하도록 구성할 수 있습니다.

구성 요소(Building Blocks)
검색기(Retrievers): 검색기는 쿼리가 주어질 때 지식 기반(즉, 인덱스)에서 관련 컨텍스트를 효율적으로 검색하는 방법을 정의합니다. 특정 검색 로직은 다양한 인덱스에 따라 다르며, 가장 인기 있는 것은 벡터 인덱스에 대한 밀집 검색입니다.
노드 포스트프로세서(Node Postprocessors): 노드 포스트프로세서는 노드 세트를 받아 변환, 필터링 또는 재랭킹 로직을 적용합니다.
응답 합성기(Response Synthesizers): 응답 합성기는 사용자 쿼리와 검색된 텍스트 청크 세트를 사용하여 LLM에서 응답을 생성합니다.
파이프라인
쿼리 엔진: 쿼리 엔진은 데이터에 대해 질문을 할 수 있는 엔드 투 엔드 파이프라인입니다. 자연어 쿼리를 입력 받아 응답을 반환하며, 검색되고 LLM에 전달된 참조 컨텍스트도 함께 제공합니다.
채팅 엔진: 채팅 엔진은 데이터와 대화를 나누기 위한 엔드 투 엔드 파이프라인입니다(단일 질문 & 답변 대신에 여러 번의 왕복).
에이전트: 에이전트는 일련의 도구를 통해 세계와 상호 작용하는 LLM으로 구동되는 자동 결정 메이커입니다. 에이전트는 쿼리 엔진이나 채팅 엔진과 동일한 방식으로 사용될 수 있습니다. 주요 차이점은 에이전트가 예정된 로직을 따르는 대신 최적의 행동 순서를 동적으로 결정한다는 것입니다. 이로 인해 더 복잡한 작업을 수행할 수 있는 추가적인 유연성을 제공합니다.
Next Steps
- tell me how to customize things.
- curious about a specific module? Check out the module guides 👈
- have a use case in mind? Check out the end-to-end tutorials