 | ChromaDB 도우미 이 서비스는 Python과 ChromaDB 전문 지식을 갖춘 소프트웨어 엔지니어로, ChromaDB를 사용하여 대규모 언어 모델 기반 AI 애플리케이션에서 문서를 저장하고 검색하는 데 도움을 제공합니다. |
Chroma DB Tutorial: A Step-By-Step Guide
An Overview of ChromaDB: The Vector Database
Basic embedding retrieval with Chroma
Chroma DB는 벡터 임베딩의 저장 및 검색을 위해 설계된 오픈 소스 벡터 저장 시스템(벡터 데이터베이스)입니다. 주요 기능은 대규모 언어 모델(LLM)에 의해 후속 사용을 위해 관련 메타데이터와 함께 임베딩을 저장하는 것입니다. 또한, 텍스트 데이터를 처리하는 의미론적 검색 엔진의 기반이 될 수 있습니다. 벡터 데이터베이스는 비구조화 및 반구조화 데이터의 대량 관리에 이상적인 해결책을 제공합니다.
여러 소스를 기반으로 종합된 개요는 다음과 같습니다:
- 데이터의 성격:
- ChromaDB는 벡터 데이터, 특히 임베딩을 처리하기 위해 고안되었으며, 이러한 데이터는 대형 언어 모델(Large Language Models, LLMs)과 같은 다른 모델에 의해 사용되거나 벡터 검색 도구로 단순히 사용될 수 있습니다.
- 벡터 형태로 데이터를 저장하여 고급 머신 러닝 알고리즘의 작동을 용이하게 하고, 추천 시스템, 이미지 인식, 자연어 처리와 같은 AI 응용 프로그램에 중요한 고도의 유사성 검색을 가능하게 합니다.
- 핵심 기능:
- ChromaDB의 주요 기능은 임베딩 벡터를 저장, 관리, 검색하는 것으로, 이러한 벡터는 텍스트, 오디오, 비디오와 같은 비구조화된 데이터를 머신 러닝 모델이 사용할 수 있는 형태로 인코딩하는 데 사용됩니다. 이러한 인코딩과 검색은 자연어, 이미지 인식 등과 관련된 사용 사례에 매우 유익합니다.
- 핵심 API는 데이터베이스와 상호 작용하기 위한 네 가지 명령어로 구성되어 있으며, 컬렉션(관계형 데이터베이스의 테이블과 유사)을 생성하고, 컬렉션에 문서를 추가하며, 컬렉션을 쿼리하는 기능을 제공합니다. API는 또한 행 기반 작업에 대한 지원이 곧 제공될 것임을 나타냅니다.
- 응용 프로그램:
- ChromaDB는 빠른 벡터 유사성 검색이 중요하고 데이터가 단일 기기에 저장될 수 있는 시나리오에서 뛰어납니다. 이는 벡터 검색 기능이 필요한 애플리케이션에 대해 단순함을 선호하는 특징으로, 기능이 풍부한 API보다는 단순함을 선호합니다.
- 통합 및 개발:
- ChromaDB는 LangChain, LlamaIndex, OpenAI와 같은 다른 기술과 통합할 수 있으며, 이는 다양한 플랫폼과 사용 사례에서의 유용성을 확장합니다. 또한 Apache 2.0 라이선스에 따른 오픈 소스 프로젝트로, 커뮤니티의 기여를 통한 개발을 장려합니다.
이 정보의 결합은 ChromaDB의 기본적인 측면과 기능을 개요하며, AI 중심의 응용 프로그램에서 벡터 데이터를 관리하는 데 제공하는 설계 철학과 가치에 대한 이해를 제공합니다.

벡터 스토어란 무엇인가요?
벡터 스토어는 벡터 임베딩을 효율적으로 저장하고 검색하기 위해 명시적으로 설계된 데이터베이스입니다. 이러한 스토어는 기존의 데이터베이스(예: SQL)가 큰 벡터 데이터를 저장하고 쿼리하는 데 최적화되지 않았기 때문에 필요합니다.
임베딩은 데이터(보통 텍스트와 같은 비구조화 데이터)를 높은 차원의 공간 내에서 수치 벡터 형식으로 나타냅니다. 기존의 관계형 데이터베이스는 이러한 벡터 표현을 저장하고 검색하는 데 잘 적합하지 않습니다.
벡터 스토어는 유사성 알고리즘을 사용하여 인덱싱하고 유사한 벡터를 빠르게 검색할 수 있습니다. 이를 통해 애플리케이션은 대상 벡터 쿼리가 주어진 경우 관련 벡터를 찾을 수 있습니다.
개인화된 챗봇의 경우 사용자는 생성 AI 모델에 대한 프롬프트를 입력합니다. 그런 다음 모델은 유사성 검색 알고리즘을 사용하여 문서 컬렉션 내에서 유사한 텍스트를 검색합니다. 그런 다음 결과 정보를 사용하여 매우 개인화되고 정확한 응답을 생성합니다. 이는 벡터 스토어 내에서 임베딩 및 벡터 인덱싱을 통해 가능하게 됩니다.
Chroma DB는 어떻게 작동하나요?
- 먼저, 관계형 데이터베이스의 테이블과 유사한 컬렉션을 생성해야 합니다. 기본적으로 Chroma는 all-MiniLM-L6-v2를 사용하여 텍스트를 임베딩으로 변환하지만, 다른 임베딩 모델을 사용하도록 컬렉션을 수정할 수 있습니다.
- 메타데이터와 고유 ID와 함께 텍스트 문서를 새로 생성된 컬렉션에 추가합니다. 컬렉션이 텍스트를 받으면 자동으로 임베딩으로 변환됩니다.
- 텍스트 또는 임베딩으로 컬렉션을 쿼리하여 유사한 문서를 받습니다. 또한 메타데이터를 기반으로 결과를 필터링할 수도 있습니다.
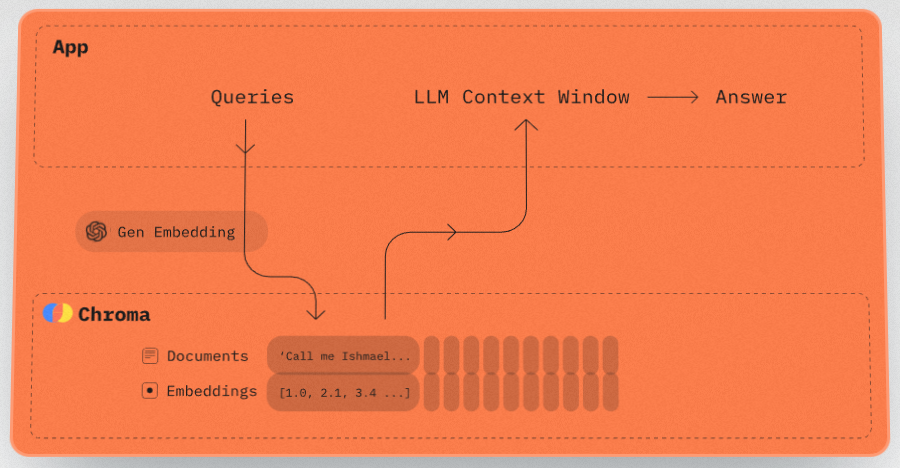
Chroma를 이용한 기본 임베딩 검색
여기서 임베딩을 사용하여 정보를 저장하고 검색하는 Chroma의 가장 기본적인 사용법을 보여줍니다. 이 핵심 구성 요소는 많은 강력한 AI 응용 프로그램의 핵심입니다.
임베딩이란 무엇인가요?
임베딩은 모든 종류의 데이터를 나타내는 인공 지능 네이티브 방식이며, 이로 인해 모든 종류의 인공 지능 기반 도구와 알고리즘을 사용하는 데 이상적입니다. 이들은 텍스트, 이미지를 나타낼 수 있으며 곧 오디오와 비디오도 나타낼 수 있습니다.
임베딩을 생성하려면 데이터를 임베딩 모델에 입력하고, 이 모델은 숫자 벡터를 출력합니다. 모델은 ‘유사한’ 데이터, 예를 들어 유사한 의미의 텍스트나 유사한 내용의 이미지의 경우 서로 가까운 벡터를 생성하도록 훈련됩니다.
임베딩과 검색
임베딩의 유사성 속성을 사용하여 정보를 검색할 수 있습니다. 예를 들어, 특정 주제와 관련된 문서를 찾거나 주어진 이미지와 유사한 이미지를 찾을 수 있습니다. 키워드나 태그를 검색하는 대신, 유사한 의미론적 의미를 가진 데이터를 찾아 검색할 수 있습니다.
pip install -Uq chromadb numpy datasets
예제 데이터셋
데모로 SciQ 데이터셋을 사용하며, 이는 HuggingFace에서 이용할 수 있습니다.
HuggingFace의 데이터셋 설명:
SciQ 데이터셋에는 물리학, 화학, 생물학 등에 관한 13,679개의 크라우드소싱된 과학 시험 문제가 포함되어 있습니다. 문제들은 각각 4개의 답변 옵션을 가진 객관식 형식으로 되어 있습니다. 대부분의 문제에는 정답에 대한 지원 증거를 제공하는 추가 단락이 포함되어 있습니다.
여기서 주어진 질문에 대한 지원 증거를 검색하는 방법을 보여 드리겠습니다.
# HuggingFace에서 SciQ 데이터셋 가져오기
from datasets import load_dataset
dataset = load_dataset("sciq", split="train")
# 지원이 있는 질문만 포함하도록 데이터셋 필터링
dataset = dataset.filter(lambda x: x["support"] != "")
print("지원이 있는 질문의 수: ", len(dataset))
Chroma에 데이터 로딩
Chroma는 내장된 임베딩 모델을 포함하고 있어 텍스트를 로드하는 것이 간단합니다.
몇 줄의 코드만으로 SciQ 데이터셋을 Chroma에 로드할 수 있습니다.
import chromadb
# Chroma를 가져와서 클라이언트를 인스턴스화합니다. 기본 Chroma 클라이언트는 일시적이며, 디스크에 저장하지 않습니다.
client = chromadb.Client()
# 지원 증거를 저장하기 위해 새로운 Chroma 컬렉션을 생성합니다. 임베딩 함수를 지정할 필요가 없으며 기본값이 사용됩니다.
collection = client.create_collection("sciq_supports")
# 이 데모를 위해 처음 100개의 지원을 임베드하고 저장합니다
collection.add(
ids=[str(i) for i in range(0, 100)], # IDs are just strings
documents=dataset["support"][:100],
metadatas=[{"type": "support"} for _ in range(0, 100)
],
)
데이터 쿼리
데이터가 로드되면, 데이터셋의 질문에 대한 지원 증거를 찾기 위해 Chroma를 사용할 수 있습니다.
이 예에서는 임베딩 유사도 점수에 따라 가장 관련성 있는 결과를 검색합니다.
Chroma는 유사성 계산과 가장 관련성 있는 결과 찾기를 처리해 주므로, 애플리케이션 구축에 중점을 둘 수 있습니다.
results = collection.query(
query_texts=dataset["question"][:10],
n_results=1)
질의 질문과 검색된 지원을 함께 표시합니다.
for i, q in enumerate(dataset['question'][:10]):
print(f"Question: {q}")
print(f"Retrieved support: {results['documents'][i][0]}")
print()