*RAG 2.0 : Your AI’s Scattered Brain Just Got Organized
*RAG 2.0: Retrieval Augmented Language Models
언어 모델은 엄청난 진보를 이루었지만, 중요한 단점들도 존재합니다. 이러한 단점들 중 많은 부분을 해결할 수 있는 한 가지 방법은 검색 보완(retrieval augmentation)입니다. 검색 보완 생성(Retrieval Augmented Generation, RAG) 파이프라인에 대해 많은 논문과 기사가 작성되었으며, 이 기술 자체는 매우 흥미롭습니다. 하지만 오늘은 이 기술의 미래에 대해 한 단계 더 나아가 살펴보려 합니다. 만약 우리가 훈련 가능한 검색기를 갖춘 모델을 생성할 수 있다면 어떨까요? 더 나아가, 전체 RAG 파이프라인을 LLM처럼 미세 조정할 수 있게 만든다면 어떨까요?
현재의 RAG의 문제점은 그 구성 요소들이 완벽하게 조화롭지 않다는 것입니다. 마치 프랑켄슈타인의 괴물처럼, 부분적으로는 작동하지만 전체적으로는 조화롭지 못하고 서로 최적화되지 않은 상태로 작동합니다. 그래서 프랑켄슈타인 RAG의 모든 문제를 해결하기 위해, RAG 2.0에 대한 심층적인 탐구를 시작해 보겠습니다.
RAG 2.0은 기존의 RAG 파이프라인을 개선하여 각 부분이 서로 더 잘 맞물리도록 하는 것을 목표로 합니다. 이를 통해 더 자연스럽고 효과적인 정보 검색 및 생성이 가능해질 것입니다. 이러한 접근 방식은 모델이 더 많은 맥락을 이해하고, 더 정확한 정보를 검색하여 사용자에게 더 정확하고 유용한 답변을 제공할 수 있게 할 것입니다.
What Are RAGs?
RAG(Retrieval Augmented Generation)는 대규모 언어 모델(LLMs)에 추가적인 맥락을 제공하여 더 정확하고 구체적인 응답을 생성할 수 있게 하는 기술입니다. 일반적으로 LLM들은 대중적으로 접근 가능한 데이터를 통해 훈련되며, 독립적으로 매우 지능적인 시스템이지만, 특정 질문에 대한 맥락이 부족하여 그에 대한 답을 제공하지 못할 때가 많습니다. RAG는 이러한 질문에 정확히 답할 수 있는 필요한 맥락을 제공합니다.
RAG는 새로운 지식이나 능력을 LLM에 삽입하는 방법이지만, 이러한 지식 삽입은 영구적이지 않습니다. LLM에 새로운 지식이나 능력을 추가하는 또 다른 방법은 특정 데이터에 맞게 LLM을 미세 조정하는 것입니다.
미세 조정을 통해 새로운 지식을 추가하는 것은 까다롭고 비용이 많이 들며 영구적입니다. 심지어 미세 조정을 통해 추가된 새로운 능력은 이전에 모델이 가진 지식에도 영향을 미칠 수 있습니다. 미세 조정 과정에서는 어떤 가중치가 변경될지, 어떤 능력이 증가하거나 감소할지를 제어할 수 없습니다.
이제, 미세 조정, RAG, 또는 두 가지의 조합을 선택하는 것은 완전히 수행하려는 작업에 달려 있습니다. 모든 상황에 맞는 단일 해결책은 없습니다.
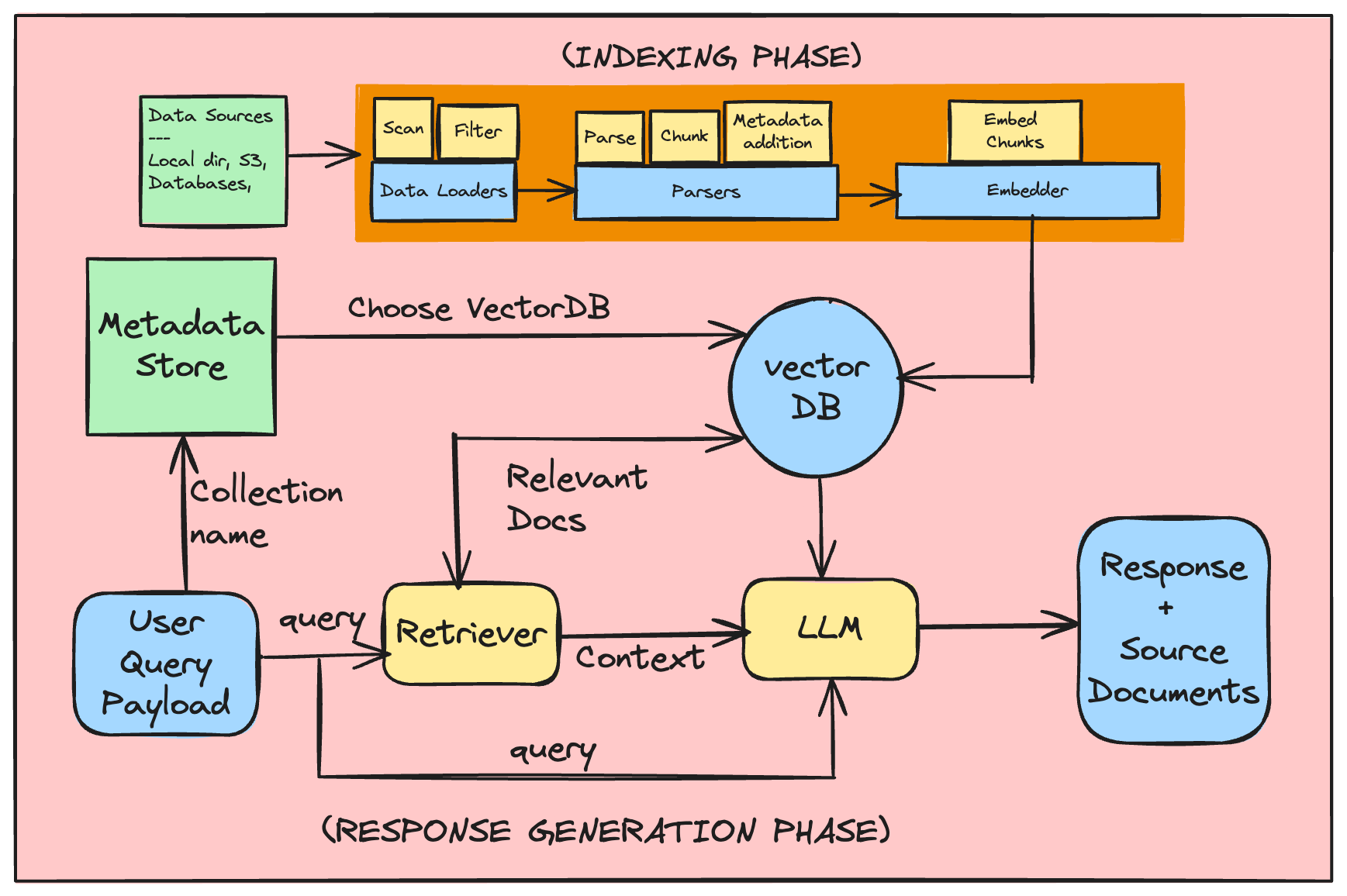
RAG의 작동 방식은 다음과 같습니다:
- 문서를 균일한 크기의 청크로 분할합니다.
- 각 청크의 원시 텍스트를 생성합니다.
- 인코더(예: OpenAI의 Embeddings, sentence_transformer)를 사용하여 각 청크에 대한 임베딩을 생성하고 데이터베이스에 저장합니다.
- 가장 유사한 인코딩된 청크들의 상위 K개를 찾고, 그 청크들의 원시 텍스트를 가져와서 프롬프트와 함께 생성기에 맥락으로 제공합니다.

What RAG 2.0 Achieves?
RAG 2.0은 다양한 축에서 기존의 RAG 시스템과 비교하여 상당한 개선을 이루었습니다. Contextual.AI가 설명하는 대로, RAG 2.0은 다음과 같은 몇 가지 주요 영역에서의 성능을 강화하였습니다:
- 오픈 도메인 질문 응답: RAG 2.0은 자연어 질문(Natural Questions, NQ) 및 트리비아 QA(TriviaQA) 데이터셋을 사용하여 각 모델의 관련 지식 검색 및 정확한 답변 생성 능력을 평가합니다. 또한 단일 단계 검색 설정에서 HotpotQA(HPQA) 데이터셋을 사용하여 모델을 평가합니다. 이러한 데이터셋에서는 정확한 일치(Exact Match, EM) 지표를 사용하여 성능을 측정합니다.
- 신뢰성: HaluEvalQA와 TruthfulQA를 사용하여 각 모델이 검색된 증거에 기반을 둔 채로 유지하고 환상을 얼마나 적게 만들어내는지를 측정합니다. 이는 모델이 정보를 왜곡하거나 잘못된 정보를 생성하는 것을 최소화하는 데 중요합니다.
- 신선도: RAG 2.0은 웹 검색 색인을 사용하여 빠르게 변화하는 세계 지식에 일반화할 수 있는 능력을 측정하고, 최근에 도입된 FreshQA 벤치마크에서의 정확도를 보여줍니다. 이는 모델이 최신 정보에 대응할 수 있는 능력을 의미합니다.
이러한 축은 모두 생산 수준의 RAG 시스템을 구축하는 데 중요합니다. RAG 2.0은 GPT-4나 Mixtral과 같은 최신 오픈 소스 모델을 사용하여 구축된 강력한 프로즌 RAG 시스템에 비해 성능이 크게 향상되었다는 것을 보여줍니다. 이러한 개선을 통해 RAG 2.0은 더 정확하고, 신뢰할 수 있으며, 현실 세계의 변화에 더 잘 적응할 수 있는 모델을 제공합니다.


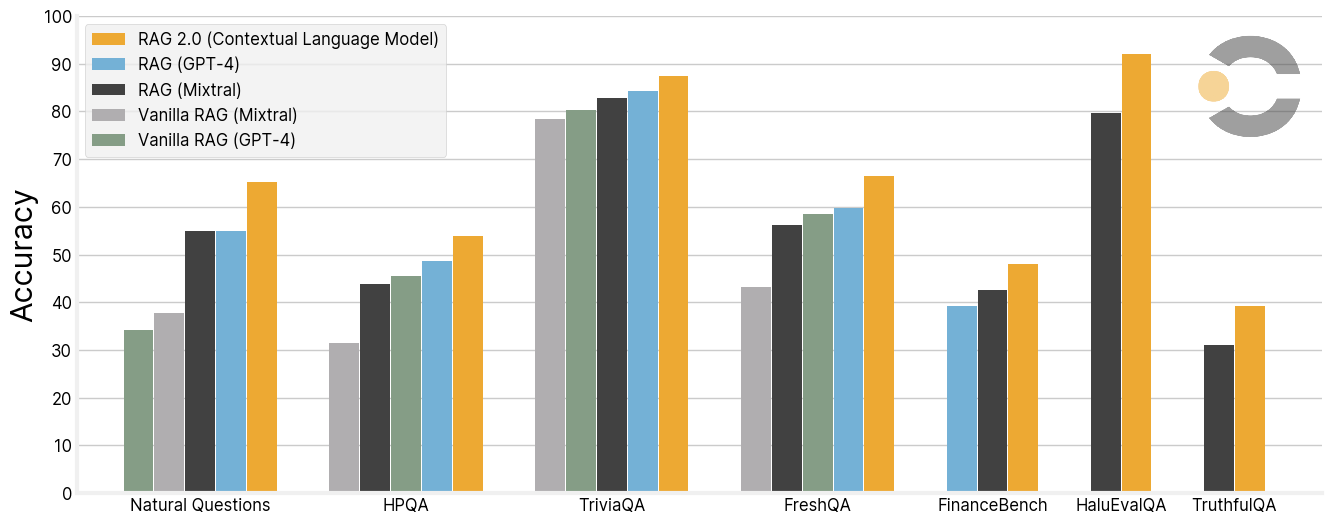
이 이미지에 나타난 표는 다양한 지식 집약적 벤치마크를 통해 Contextual Language Model RAG 2.0과 다른 RAG 시스템들의 성능을 비교하고 있습니다. 각 벤치마크는 오픈 도메인 질문 응답(Open Domain Question Answering), 신뢰성(Faithfulness), 신선도(Freshness) 등의 축을 중심으로 성능을 측정하고 있습니다.
- NQ (Natural Questions): RAG 2.0은 65.3%로 나타나, 다른 RAG 모델들에 비해 상당히 높은 성능을 보여줍니다.
- TriviaQA: RAG 2.0이 87.5%로 가장 높은 성능을 달성했습니다.
- HPQA (HotpotQA): 이 벤치마크에서는 54.0%로, 다른 모델들과 비교했을 때 상대적으로 균일한 성능을 보여줍니다.
- TruthfulQA: 39.3%로, 이 축에서는 다소 낮은 성능을 보여주나, 다른 모델들과 비슷한 수준입니다.
- HaluEvalQA: RAG 2.0은 92.1%로, 매우 높은 신뢰성을 가지고 있음을 보여줍니다.
- FreshQA: 66.4%로, 신선도 면에서도 강력한 성능을 나타냅니다.
이 결과들은 RAG 2.0이 다양한 벤치마크에 걸쳐서 뛰어난 성능을 보여주며, 특히 HaluEvalQA에서의 높은 신뢰성과 FreshQA에서의 신선도를 통해 빠르게 변화하는 세계 지식에 잘 적응하는 것을 보여줍니다.
How Does RAG Solve Issues of Intelligence?
RAG(Retrieval Augmented Generation)는 언어 모델의 한계를 극복하기 위해 정보 검색(retrieval)을 기반으로 동작하는 시스템입니다. RAG 시스템은 대규모 언어 모델(LLM)과 비모수적(non-parametric) 검색 부분을 결합한 반모수적(semi-parametric) 시스템이라고 할 수 있습니다. LLM은 그 가중치나 파라미터에 정보를 인코딩된 형태로 저장하고 있지만, 나머지 시스템은 그러한 지식을 정의하는 파라미터가 없습니다.
RAG가 지능 문제를 해결하는 방법은 다음과 같습니다:
- 인덱스 교체를 통한 맞춤화: 인덱스(즉, LLM 내의 특정 정보)를 교체함으로써, 정보가 오래되지 않고 인덱스 내의 정보를 수정할 수 있는 맞춤화를 가능하게 합니다.
- 근거 마련: 이러한 인덱스로 LLM을 근거지게 함으로써, 환상적인 생성물(hallucination)이 적어지고, 출처를 가리키며 인용과 귀속을 할 수 있게 됩니다.
즉, 원리적으로 RAG는 LLM이 더 잘 수행할 수 있도록 더 나은 맥락화를 생성할 수 있는 능력을 제공합니다.
하지만, 이러한 원리가 실제로 간단하게 적용되는 것은 아닙니다. 현대적이고 확장 가능한 RAG 파이프라인을 만들기 위해서는 해결해야 할 여러 가지 문제들이 있습니다. 이러한 문제들은 다음과 같습니다:
- 정보의 신선도: 세계는 끊임없이 변화하므로, LLM이 학습한 데이터에서부터 현재까지의 격차를 어떻게 해결할 것인가.
- 검색 결과의 정확성과 관련성: 검색된 정보가 현재의 질문과 얼마나 관련이 있는지, 그리고 얼마나 정확한지를 평가하는 것.
- 확장성과 효율성: 대용량 데이터에 대해 빠르고 정확한 검색을 수행하면서 시스템을 확장하는 방법.
- 데이터의 다양성과 편향: 데이터셋의 다양성과 편향을 관리하여 LLM이 균형 잡힌 지식을 가지고 응답할 수 있게 하는 것.
이러한 복잡한 문제들을 해결하기 위해 연구자들은 계속해서 RAG 시스템을 발전시키고 있으며, RAG 2.0과 같은 새로운 모델은 이러한 문제들에 대응하기 위해 설계되었습니다.

현재의 프로즌 RAG 시스템은 비교적 단순한 수준에서 작동하며, 복잡한 맥락을 필요로 하는 고난도 작업을 수행하는 데 있어 한계를 가지고 있습니다. 프로즌 RAG는 특정 시점에서 정보를 검색하기 위한 인덱스를 고정한 상태로 사용하는데, 이것은 시스템이 새로운 정보를 흡수하고, 적응하며, 사용자 정의 맥락을 심층적으로 통합하는 데 제한적일 수 있습니다.
프로즌 RAG의 주요 단점은 다음과 같습니다:
- 맥락의 신선도: 프로즌 RAG는 검색 인덱스가 고정되어 있기 때문에, 최신 정보를 반영하지 못할 수 있습니다. 세계 지식이 빠르게 변화하는 가운데, 시스템이 이 변화에 맞추어 정보를 갱신하지 않으면, 결과의 신선도가 떨어집니다.
- 복잡한 맥락 이해: 사용자 정의 맥락이 필요한 복잡한 작업을 처리할 때, 프로즌 RAG는 충분히 유연하지 않아서 이를 적절히 처리하지 못할 수 있습니다.
- 고정된 지식의 확장성 문제: 고정된 지식 인덱스를 가진 시스템은 새로운 지식이나 도메인에 대해 학습하고 확장하는 데 한계가 있습니다.
- 맞춤화의 부족: 프로즌 RAG 시스템은 특정 사용자나 도메인에 맞춘 맞춤화를 수행하는 데 제한적일 수 있습니다.
이러한 문제들에 대응하기 위해 RAG 2.0과 같은 발전된 시스템은 가변적인 검색 인덱스를 사용하거나, 인덱스를 지속적으로 업데이트하는 메커니즘을 구현하여 시스템의 신선도를 유지하고, 복잡한 맥락을 이해하며, 다양한 사용자 요구에 맞출 수 있는 능력을 갖추고자 합니다. RAG 2.0은 또한 모델 자체를 미세 조정할 수 있어, 특정 작업에 맞춘 지식과 맥락을 제공하는 것을 가능하게 할 것으로 기대됩니다.