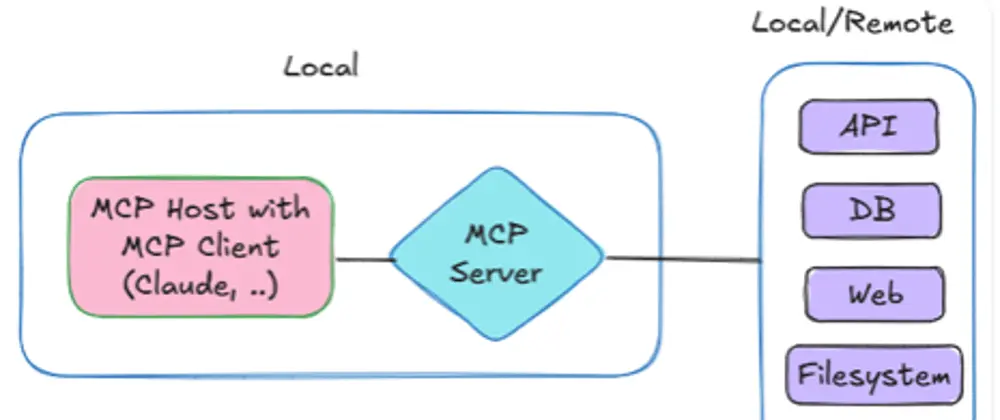
기반의 문서 처리 시스템 구축")



n8n은 다양한 데이터 소스를 활용하여 자동화된 워크플로우를 구성할 수 있는 강력한 도구입니다. 특히, Merge 노드를 사용하면 SQL의 JOIN 기능과 유사하게 여러 데이터 세트를 결합할 수 있습니다. 이를 활용하면 데이터를 더욱 효과적으로 조작하고 필요한 정보를 쉽게 통합할 수 있습니다.
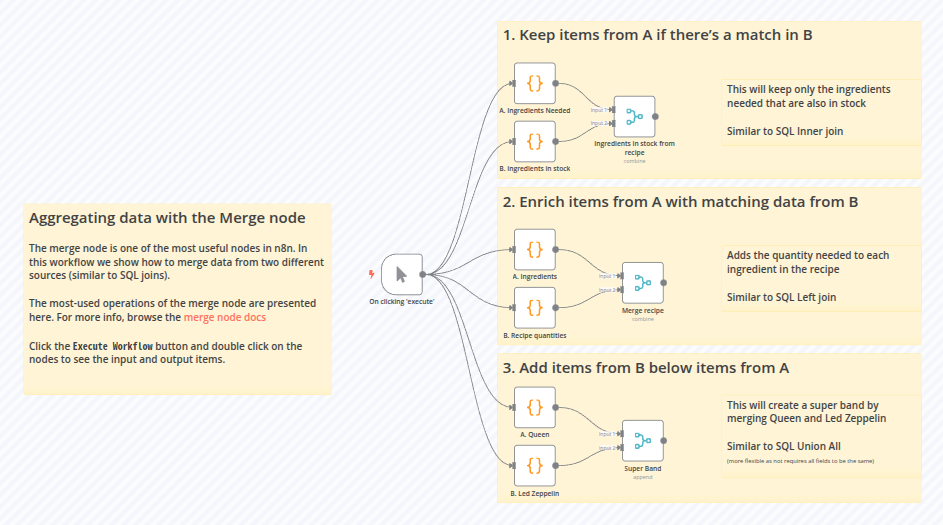
Merge 노드란?
Merge 노드는 두 개의 서로 다른 데이터 세트를 하나로 합치는 데 사용됩니다. 이를 통해 다음과 같은 작업을 수행할 수 있습니다.
- 데이터 세트 추가 (Appending Data Sets): 서로 다른 소스에서 가져온 데이터를 결합
- 새로운 항목만 유지 (Keep Only New Items): 기존 데이터와 비교하여 새로운 항목만 필터링
- 기존 항목만 유지 (Keep Only Existing Items): 두 데이터 세트에서 일치하는 항목만 유지
워크플로우 작동 방식
n8n의 Merge 노드를 활용한 워크플로우는 세 개의 주요 분기로 나뉘며, 각각 특정한 데이터 병합 기능을 수행합니다.
1. A 데이터에서 B에 일치하는 항목만 유지하기
(Keep items from A if there’s a match in B)
- A 데이터 세트(예: 필요한 재료 목록)와 B 데이터 세트(예: 현재 재고 목록)를 비교합니다.
- B 데이터 세트에 존재하는 항목만 유지하여 불필요한 데이터를 제거합니다.
- SQL의 INNER JOIN과 유사한 방식으로 작동합니다.
2. A 데이터에 B 데이터를 추가하여 보강하기
(Enrich items from A with matching data from B)
- A 데이터 세트(예: 레시피 재료 목록)와 B 데이터 세트(예: 필요한 수량)를 결합합니다.
- 각 재료에 필요한 수량을 추가하여 데이터를 보강합니다.
- SQL의 LEFT JOIN과 유사한 방식으로 작동합니다.
3. B 데이터 세트를 A 데이터 아래에 추가하기
(Add items from B below items from A)
- 두 개의 서로 다른 데이터 세트(A: Queen, B: Led Zeppelin)를 단순히 하나의 목록으로 합칩니다.
- 이 방식은 SQL의 UNION ALL과 유사하게 동작하며, 필드 구성이 동일해야 합니다.
n8n의 Merge 노드를 활용하면 SQL의 JOIN과 유사한 방식으로 데이터를 쉽게 병합할 수 있습니다.
- 필요한 데이터만 유지하여 불필요한 정보를 제거할 수 있습니다.
- 추가 정보를 결합하여 데이터 세트를 확장할 수 있습니다.
- 여러 데이터 세트를 하나로 합쳐 새로운 리스트를 구성할 수 있습니다.
이러한 기능을 활용하면 n8n에서 더욱 강력한 데이터 통합 및 자동화 프로세스를 구축할 수 있습니다!