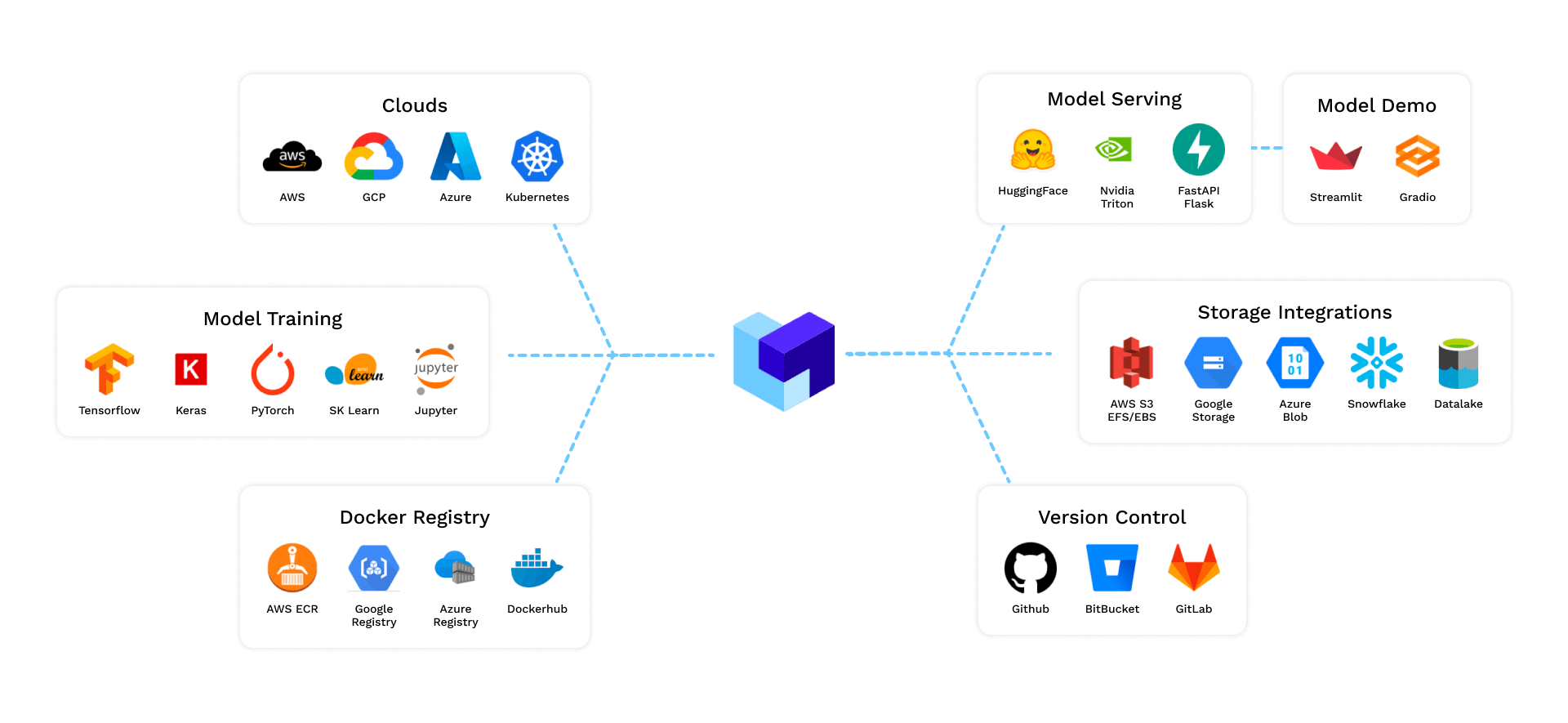
과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")




How to build a chatbot using open-source LLMs like Llama 2 and Falcon
*How to Build an Intelligent QA Chatbot on your data with LLM or ChatGPT
이 블로그에서는 오픈소스 LLMs를 사용하여 챗봇을 만드는 방법을 배울 것입니다. 우리는 Lit-GPT와 LangChain을 사용할 것입니다. Lit-GPT는 튜닝과 추론을 위한 오픈소스 LLMs의 최적화된 모음입니다. 이는 Falcon, Llama 2, Vicuna, LongChat 및 기타 성능이 뛰어난 오픈소스 대형 언어 모델을 지원합니다.
Advancements of LLMs in Chatbot Development
챗봇은 전자 상거래, 고객 서비스, 의료 분야를 포함한 많은 산업에 필수적으로 통합되어 왔습니다. 대형 언어 모델의 발전으로 챗봇을 구축하는 것이 예전보다 훨씬 쉬워졌습니다. 챗봇은 지식 베이스에서 관련 정보를 찾아 사용자에게 제시할 수 있습니다. 데이터베이스에 연결하여 벡터 데이터베이스에서 질의하고 문서를 기반으로 질문에 답할 수 있습니다.
LLMs는 주어진 프롬프트를 기반으로 답변을 생성하는 능력이 있습니다. 이제 LLMs는 전체 문서의 내용을 파악하고 해당 문서를 기반으로 질문에 답할 수 있습니다. In-context learning은 모델의 가중치를 변경하지 않고 추론 시점에서 새로운 작업을 해결하는 방법을 LLM에게 학습시킵니다. 프롬프트에는 모델이 수행할 것으로 예상되는 작업의 예가 포함됩니다. 프롬프트 엔지니어링에 대한 토론은 훨씬 더 길어질 수 있지만, 우리는 첫 MVP 챗봇을 만드는 방법에 중점을 둘 것입니다.
Making conversation with an LLM
기본적인 대형 언어 모델(LLMs)은 다음 단어를 예측하도록 훈련됩니다. 이러한 LLMs는 사용자의 입력, 문맥, 그리고 예상 출력을 포함하는 지시 데이터셋에서 세부 조정(finetuning)을 받아 사람의 지시를 따르고 관련된 응답을 생성합니다. LLM을 챗봇처럼 작동하게 만드는 지시 프롬프트(instruction prompt)의 예시는 아래에 제공됩니다.
호기심 많은 사용자와 인공 지능 어시스턴트 간의 대화.
어시스턴트는 사용자의 질문에 도움이 되며, 상세하고 공손한 답변을 제공합니다.사용자: {input}
어시스턴트:
첫 두 줄은 LLM에 지시를 내리는 역할을 하며, 이를 통해 어시스턴트 챗봇이 도움이 되고, 상세하며, 공손한 응답을 제공하도록 지시합니다. 세 번째 줄인 ‘사용자: {input}’은 사용자의 입력을 나타냅니다. 여기서 {input}은 사용자의 질의로 대체될 것입니다. 그런 다음 LLM은 사용자의 프롬프트에 대한 응답을 생성하기 위해 다음 단어를 예측하기 시작합니다.
이 튜토리얼에서는 지시-조정된 모델(instruction-tuned model)을 사용하고 사용자 입력을 프롬프트로 제공할 것입니다. 위에서 정의한 프롬프트를 사용하여 첫 번째 챗봇을 만들어 봅시다. 우리는 16K (~12K 단어)의 문맥 길이를 가진 챗 데이터셋에서 훈련된 LLaMA와 유사한 모델인 LongChat을 사용할 것입니다.
우리는 프롬프트 템플릿을 longchat_prompt_template로 정의할 것이며, 각 사용자 질의에 대해 문자열을 형식화하고 모델에 공급할 것입니다.
longchat_template = """호기심 많은 사용자와 인공 지능 어시스턴트 간의 대화. 어시스턴트는 사용자의 질문에 도움이 되며, 상세하고 공손한 답변을 제공합니다.
USER: {input}
ASSISTANT:"""
output = longchat_template.format(input="My name is Aniket?")우리는 llm-inference 라이브러리를 사용할 것입니다. 이것은 Lit-GPT에 대한 래퍼로, 모델을 로드하고 생성 메서드를 사용하기 위한 API 인터페이스를 제공합니다. 먼저 bnb.nf4를 사용하여 4비트 양자화로 모델을 로드하며, 이는 약 6GB의 GPU 메모리를 필요로 할 것입니다.

다음으로, 사용자 입력이 포함된 형식화된 템플릿에서 응답을 생성하기 위해 Lit-GPT 채팅 스크립트를 위한 API 인터페이스인 model.chat 메서드를 사용하세요.

Assistant doesn’t have a memory
우리의 챗봇은 훌륭하게 작동하지만 문제가 있습니다: 우리의 어시스턴트는 상태가 없으며 이전의 상호작용을 잊어버립니다. 아래에서 볼 수 있듯이, 사용자는 봇에게 자신의 이름을 알려주고, 두 번째 상호작용에서 “내 이름은 무엇인가요?”라고 물어봅니다. 그러나 어시스턴트는 메모리 부족으로 인해 요청된 정보를 제공할 수 없습니다.

이 문제를 해결하는 것은 그리 어렵지 않습니다. LLM에게 프롬프트를 통해 문맥을 제공하면, 그 문맥을 참조하여 답변할 수 있습니다. 우리는 대화의 히스토리를 저장하고 그것을 프롬프트에 삽입할 수 있습니다. 아래의 예제처럼 사용자가 자신의 이름을 문맥으로 제공하면, 모델은 그 후의 질문에서 그 이름에 대해 답변할 수 있었습니다.

메모리와 프롬프트 – 지속적인 대화 유지하기
LLMs는 언어를 이해하고 정보를 검색하는 능력을 가진 상태가 없는 인터페이스입니다. 그러나 LLMs는 기억력이 없으므로 이전의 요청에 의해 이후의 질의가 영향을 받지 않습니다. 그러므로, 한번의 질의에서 자신의 이름을 제공하고 LLM에게 그것을 다음 질의에도 기억하길 바란다면, 그것은 이루어지지 않을 것입니다.
LLMs에게 이전의 상호작용을 기억하게 하는 능력을 부여하기 위해, 대화의 히스토리를 프롬프트 템플릿 내에 모델에 대한 문맥으로 저장할 수 있습니다. 우리는 다음과 같은 프롬프트 템플릿을 만들 것입니다 –

{history}는 이전 대화로 대체되며 {input}은 사용자의 현재 질의로 대체됩니다. 우리는 각 상호작용에 대해 히스토리와 입력을 계속 업데이트합니다. LangChain은 벡터 데이터베이스에서 문맥을 조회하는 것과 같은 좀 더 고급 방법을 사용하여 프롬프트를 형식화하고 문맥을 업데이트하는데 유용한 클래스를 제공합니다.
히스토리가 계속 증가하게 되면, 프롬프트에 대한 입력 값이 길어지게 되어 처리 속도와 메모리 사용에 문제가 생길 수 있습니다. 이 문제를 해결하기 위한 몇 가지 방법이 있습니다:
- 길이 제한: 히스토리의 길이를 일정한 크기로 유지할 수 있습니다. 즉, 가장 오래된 대화부터 제거하면서 새로운 대화를 추가합니다.
- 키워드 추출: 각 대화에서 핵심적인 키워드나 문장만을 추출하여 그 정보만을 히스토리로 사용합니다. 이를 통해 대화의 본질은 유지하면서 길이를 줄일 수 있습니다.
- 문맥 벡터화: 최근의 진보된 방법 중 하나는 대화의 문맥을 벡터 형태로 압축하는 것입니다. 이 벡터는 대화의 핵심적인 정보를 포함하게 되며, 이를 다시 사용하여 프롬프트를 생성할 때 문맥 정보를 제공할 수 있습니다.
- 상태 관리 도구 사용: 일부 고급 챗봇 플랫폼들은 대화의 상태를 관리하는 도구를 제공합니다. 이 도구들은 대화 히스토리를 효과적으로 관리하고 필요한 정보만을 추출하여 사용하는 것을 가능하게 합니다.
- 다단계 질의 처리: 사용자에게 복잡한 정보나 긴 문맥을 제공하기 보다는, 간결하고 구체적인 질의를 여러 번 할 수 있게 유도하는 방식을 선택할 수도 있습니다.
이러한 방법들은 각각의 상황과 요구사항에 따라 적절히 조합되어 사용될 수 있습니다.
We will use the PromptTemplate class with history and input as variables.

You can format the longchat_prompt_template using longchat_prompt_template.format method by providing input and history .

다음으로, ConversationChain 클래스를 사용하여 대화 체인을 생성합니다. 이 클래스는 LLM, 프롬프트 템플릿, 메모리 관리 객체를 입력으로 받습니다. 우리는 ConversationBufferMemory를 사용할 것입니다. 이것은 모든 대화를 저장하고 각 상호작용마다 프롬프트 템플릿의 히스토리를 업데이트합니다.


메모리에 접근할 수 있으며 대화 객체를 사용하여 조작할 수도 있습니다. 현재 대화를 출력하려면 print(conversation.memory.buffer)를 실행하면 됩니다.

이 메모리는 각 대화 후에 문맥으로 프롬프트에 업데이트됩니다.
QA over Documents as context
챗봇은 데이터베이스에서 문서를 추출하고 주어진 문서를 문맥으로 질문에 답하는 것과 같은 더 복잡한 작업을 수행하도록 확장될 수 있습니다. 이 기술로 문서 QnA 봇을 만들 수 있습니다. 이 블로그에서 깊게 다루지는 않겠지만, 궁금하다면 모델 메모리를 관련 문서를 검색하는 다른 LLM으로 교체하고 프롬프트 템플릿의 문맥을 추출된 문서로 업데이트할 수 있습니다. 여기 LangChain 예제에서 더 자세한 내용을 읽을 수 있습니다.
LangChain과 같은 플랫폼에서 “QA over Documents” 기능을 사용하면 다음과 같은 기능을 수행할 수 있을 것입니다:
- 문서 검색: 사용자의 질문과 관련된 관련 문서나 정보를 데이터베이스에서 빠르게 검색합니다.
- 정보 추출: 검색된 문서에서 직접적인 답변이나 관련 정보를 추출합니다.
- 컨텍스트 기반 대답: LLM은 주어진 문서의 컨텍스트를 기반으로 사용자의 질문에 답합니다.
- 지속적인 학습: 시스템은 지속적으로 새로운 문서와 사용자의 피드백을 통해 학습하여 결과를 개선할 수 있습니다.
Conclusion
결론적으로, 대형 언어 모델의 최신 발전 덕분에 오픈 소스 LLM을 활용한 챗봇 구축이 전보다 훨씬 간단해졌습니다. LLM이 주어진 프롬프트나 심지어는 전체 문서를 기반으로 답변을 생성하는 능력은 많은 산업에 있어 필수적인 역할을 하게 되었습니다. 지시어를 조정한 모델을 사용하고 사용자의 입력을 프롬프트로 제공함으로써, 우리는 도움이 되며 상세하고 예의바른 응답을 제공하는 챗봇을 구축할 수 있습니다. 챗봇들은 기본적으로 상태를 유지하지 않지만, 대화 내역을 모델의 문맥으로 사용하여 이전 상호작용을 기억하게 할 수 있습니다. 마침내, 챗봇은 데이터베이스에서 문서를 추출하거나 주어진 문서를 바탕으로 질문에 답하는 등 더 복잡한 작업을 수행하는 방향으로 확장될 수 있습니다.
Resources
- How To Finetune GPT Like Large Language Models on a Custom Dataset
- Accelerating Large Language Models with Mixed-Precision Techniques
- Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
- Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters