과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



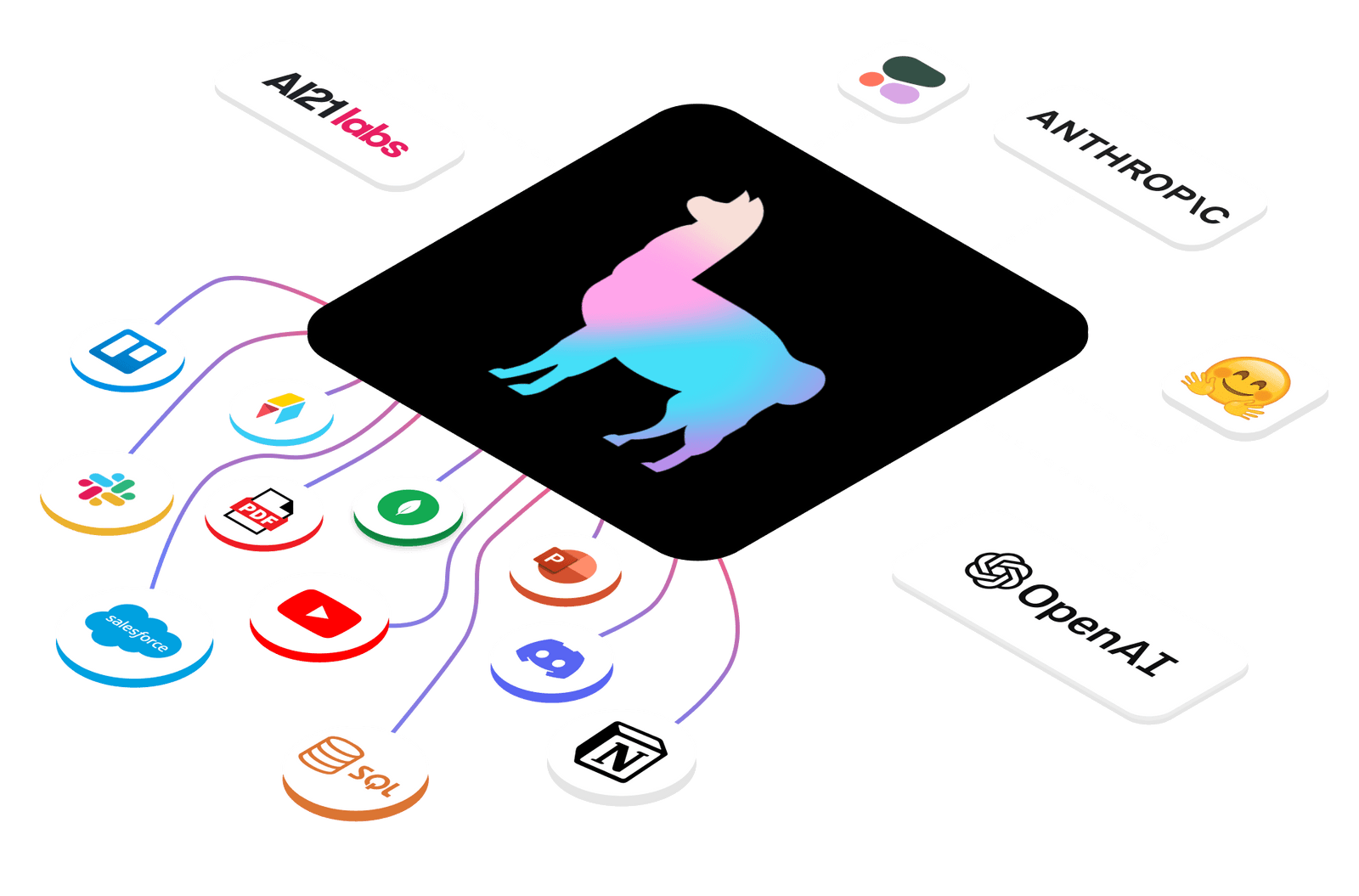
LlamaIndex(이전에 GPT Index라고 불렸음)는 대규모 언어 모델(LLM) 응용 프로그램을 위한 데이터 프레임워크로, 개인이나 도메인 특정 데이터를 취득, 구조화 및 접근할 수 있게 돕습니다. 이 프레임워크는 데이터 커넥터를 통해 다양한 데이터 소스와 형식에서 데이터를 가져와 간단한 문서 표현으로 변환하며, 이 데이터를 쉽게 검색할 수 있는 형식으로 인덱싱합니다. 또한, LlamaIndex는 사용자 정의 데이터와 LLM을 결합하기 위한 검색 증강 생성(Retrieval Augmented Generation, RAG) 패러다임을 적용하여, Q&A, 챗봇, 에이전트와 같은 LLM 기반 응용 프로그램의 구축을 지원합니다.
설치 및 설정
Pip을 통한 설치
pip install llama-index
주의: LlamaIndex는 다양한 패키지(NLTK, HuggingFace, …)를 위해 로컬 파일을 다운로드하고 저장할 수 있습니다. 이러한 파일이 저장되는 위치를 제어하려면 환경 변수 “LLAMA_INDEX_CACHE_DIR”를 사용하세요.
OpenAI 환경 설정
기본적으로 텍스트 생성을 위해 OpenAI gpt-3.5-turbo 모델을 사용하고, 검색 및 임베딩을 위해 text-embedding-ada-002를 사용합니다. 이를 사용하려면 OPENAI_API_KEY가 설정되어 있어야 합니다. OpenAI의 페이지에 로그인하여 새로운 API 토큰을 생성함으로써 API 키를 등록할 수 있습니다.
팁: 기본 LLM도 사용자 정의할 수 있습니다. LLM 제공 업체에 따라 추가적인 환경 키 및 토큰 설정이 필요할 수 있습니다.
로컬 환경 설정
OpenAI를 사용하고 싶지 않다면, 환경은 자동으로 LlamaCPP와 llama2-chat-13B를 텍스트 생성용으로, 그리고 BAAI/bge-small-en을 검색 및 임베딩용으로 사용하여 로컬에서 실행됩니다.
LlamaCPP를 사용하려면 여기에 있는 설치 가이드를 따르세요. llama-cpp-python 패키지를 설치해야 하며, 가능하다면 GPU를 지원하도록 컴파일하는 것이 좋습니다. 이렇게 하면 CPU와 GPU 간에 약 11.5GB의 메모리가 사용됩니다.
LlamaCPP는 4비트 정수 양자화를 활용하여 맥북에서 Llama 모델을 실행하도록 설계된 프로젝트입니다. 이 프로젝트는 의존성 없는 순수 C/C++를 통해 구현되어 Mac OS, Windows, Linux에서 모두 실행 가능합니다. LlamaCPP는 Python과의 인터페이스를 제공하여, OpenAI 호환 클라이언트와 함께 LlamaCPP 호환 모델을 사용할 수 있게 해주며, 로컬 환경에서 언어 모델을 실행하는데 사용됩니다.
로컬 임베딩을 사용하려면, 단순히 pip install sentence-transformers를 실행하세요. 로컬 임베딩 모델은 약 500MB의 메모리를 사용합니다.
로컬 임베딩(Local Embedding)을 사용한다는 것은, 사용자의 컴퓨터(로컬 환경)에서 텍스트 데이터를 수치형 벡터로 변환하는 작업을 수행한다는 뜻입니다. 임베딩은 텍스트 데이터를 컴퓨터가 이해하고 처리할 수 있는 형태로 변환하는 과정을 말하며, 이러한 임베딩 작업은 보통 머신 러닝 모델이나 딥 러닝 모델에 사용됩니다.
로컬 임베딩을 사용하면 인터넷 연결이 없어도 임베딩 작업을 수행할 수 있으며, 개인 데이터의 보안과 프라이버시를 보장할 수 있습니다. 또한, 로컬 환경에서 직접 임베딩 작업을 수행하면 외부 서버에 의존하지 않고, 빠른 처리 속도와 낮은 지연 시간을 달성할 수 있습니다.
로컬 임베딩을 사용하기 위해서는, 사용자의 컴퓨터에 임베딩 모델을 설치하고, 필요한 라이브러리와 도구를 설정해야 합니다. 예를 들어, 앞서 언급된
sentence-transformers라이브러리를 사용하여 pip 명령어로 설치하고, 로컬 환경에서 임베딩 모델을 실행할 수 있습니다.
다운로드
LlamaIndex 예제는 LlamaIndex 저장소의 examples 폴더에 있습니다. 먼저 이 examples 폴더를 다운로드하려고 합니다. 이를 수행하는 쉬운 방법은 저장소를 복제하는 것입니다:
$ git clone https://github.com/jerryjliu/llama_index.git
다음으로, 방금 복제한 저장소로 이동하여 내용을 확인하세요:
$ cd llama_index $ ls LICENSE data_requirements.txt tests/ MANIFEST.in examples/ pyproject.toml Makefile experimental/ requirements.txt README.md llama_index/ setup.py
이제 다음 폴더로 이동합니다.
$ cd examples/paul_graham_essay
이 폴더에는 Paul Graham의 에세이 “What I Worked On“에 대한 LlamaIndex 예제들이 포함되어 있습니다. TestEssay.ipynb에는 이미 포괄적인 예제 세트가 제공되고 있습니다. 이 튜토리얼의 목적으로, 우리는 LlamaIndex를 시작하고 실행하는 간단한 예제에 중점을 둘 수 있습니다.
인덱스 구축 및 쿼리
다음과 같이 새로운 .py 파일을 생성합니다:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
이 코드는 data 폴더 내의 문서에 대한 인덱스를 구축합니다 (이 경우에는 에세이 텍스트만 포함되어 있습니다). 그런 다음 아래 코드를 실행합니다.
query_engine = index.as_query_engine()
response = query_engine.query("작가는 자라면서 무엇을 했나요?")
print(response)
아래와 유사한 응답을 받아야 합니다: 저자는 단편소설을 썼고 IBM 1401에서 프로그래밍을 시도했습니다.
쿼리 및 이벤트 로깅을 통한 보기
Jupyter 노트북에서는 다음 코드을 사용하여 정보 및/또는 디버깅 로깅을 볼 수 있습니다:
import logging import sys logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
자세한 출력을 위해 레벨을 DEBUG로 설정하거나, 더 적은 출력을 위해 level=logging.INFO를 사용할 수 있습니다.
LLM에 대한 모든 요청을 보려면 openai 로깅 플래그를 설정할 수 있습니다:
openai.log = "debug"
이렇게 하면 openai를 통해 이루어진 모든 요청과 응답을 출력합니다. 로깅을 끄려면 다시 None으로 변경하세요.
저장 및 로딩
기본적으로 데이터는 메모리에 저장됩니다. 디스크에 저장하려면(./storage 아래에):
index.storage_context.persist()
디스크에서 다시 로드하려면:
from llama_index import StorageContext, load_index_from_storage # 저장 컨텍스트 재구성 storage_context = StorageContext.from_defaults(persist_dir="./storage") # 인덱스 로드 index = load_index_from_storage(storage_context)