




 기반의 문서 처리 시스템 구축")


ChatGPT API를 이용해 시스템을 구축하는 것은 모델에 프롬프트를 보내고 응답을 받는 것 이상의 과정을 필요로 합니다. 사용자 경험을 보장하기 위해 여러 단계의 신중한 계획, 구현, 관리를 요구합니다. 다음은 간략화된 단계별 과정입니다:
- API 이해하기: ChatGPT API의 기능과 한계를 이해하시기 바랍니다. 요청을 어떻게 보내고 응답을 어떻게 처리하는지,
temperature와max_tokens같은 매개변수를 어떻게 사용해서 출력을 조절하는지를 이해해야 합니다. - 입력 처리: 사용자의 입력을 ChatGPT API에 전송하기 전에 입력이 부적절한 내용을 포함하고 있지 않은지 확인해야 합니다. 이는 문제가 될 수 있는 문구를 확인하고 걸러내기 위해 자연어 처리(NLP) 기법을 사용하는 것을 포함할 수 있습니다.
- API 사용하기: 처리된 사용자 입력을
messages매개변수에 메시지로 API에 전달합니다.messages매개변수는 메시지 객체의 배열이며, 각 객체에는role(‘system’, ‘user’, ‘assistant’ 중 하나가 될 수 있음)과content(메시지의 내용)가 있습니다. - 응답 처리: API는 헬퍼 함수의 응답을 반환합니다. 이 응답을 적절하게 처리하고, 애플리케이션의 사용자 인터페이스에 제대로 통합되도록 해야 합니다.
- 후처리: API에서 응답을 받은 후에는 응답을 후처리해서 모든 요구 사항을 충족하는지 확인하는 것이 좋습니다. 이는 내용의 정확성, 관련성, 적절성을 확인하는 것을 포함할 수 있습니다.
- 반복적 개선: 사용자 피드백과 성능 분석을 기반으로, 구현을 반복하거나 매개변수를 조정하거나 전처리와 후처리 단계를 추가할 수 있습니다.
- 시스템 유지 관리: 시간이 지나면서 사용자 행동이 변화하고 모델이 발전함에 따라 시스템을 유지 관리하고 업데이트해야 합니다. 이는 모델을 다시 학습시키는 것, 입력과 출력 처리 단계를 업데이트하는 것, 필요에 따라 API 사용을 조정하는 것을 포함할 수 있습니다.
ChatGPT API를 효과적으로 사용하고 신중하게 시스템의 워크플로우에 통합함으로써, 대규모 언어 모델의 힘을 이용한 상호작용적이고 매력적인 애플리케이션을 만들 수 있습니다.
Language Models, the Chat Format
첫 번째 비디오에서는 대형 언어 모델(LLMs)이 어떻게 작동하는지에 대한 개요를 공유하려 합니다. 모델이 어떻게 훈련되는지, 토크나이저와 같은 세부 사항이 LLM에 프롬프트를 제공할 때 출력에 어떻게 영향을 미치는지에 대해서도 자세히 살펴보겠습니다.
또한, LLMs의 채팅 형식을 살펴보겠습니다. 이는 시스템 메시지와 사용자 메시지를 모두 지정하는 방법으로, 이 기능을 활용하여 어떤 것을 할 수 있는지 이해하는 데 도움이 됩니다.
- LLMs가 어떻게 작동하는지 이해하기: LLMs는 다양한 텍스트 샘플에서 학습합니다. 이를 통해 LLMs는 문맥에 따른 단어 사용, 문법, 심지어 특정 주제에 대한 지식과 같은 많은 언어 패턴을 학습할 수 있습니다.
- 모델 훈련: 모델은 대규모 데이터 세트에서 수많은 예제를 통해 학습하며, 이는 모델이 언어의 복잡성과 다양성을 이해하는 데 도움이 됩니다. 이 과정은 굉장히 많은 컴퓨팅 자원을 필요로 합니다.
- 토크나이저 이해: 토크나이저는 텍스트를 처리하고 모델이 이해할 수 있는 형식으로 변환하는 중요한 도구입니다. 이는 언어 모델의 입력과 출력 모두에 영향을 미칩니다.
- 채팅 형식 이해: 채팅 형식은 시스템 메시지와 사용자 메시지를 모두 지정할 수 있게 해줍니다. 이 형식을 이해하고 사용하면 LLM을 사용한 시스템을 더 효과적으로 구축하고 관리할 수 있습니다.
이러한 개념들을 이해하면 LLM을 더 효과적으로 활용할 수 있으며, 사용자의 경험을 향상시키고 원하는 결과를 얻는 데 도움이 됩니다. 이제 각 개념에 대해 자세히 알아보겠습니다.

대형 언어 모델(LLM)은 어떻게 작동할까요?
아마도 “I love eating”과 같은 프롬프트를 주고 이 프롬프트를 바탕으로 가능한 완성본을 LLM에게 요청하는 텍스트 생성 과정에 익숙하실 것입니다. 그러면 모델은 “크림치즈가 들어간 베이글, 혹은 엄마의 미트로프, 친구들과 외식하는 것”과 같은 답변을 제공할 수 있습니다. 그런데 이 모델은 어떻게 이런 작업을 배우게 된 것일까요?
LLM은 비지도 학습 방식, 즉 지도 없이 학습하는 방식으로 훈련됩니다. 모델은 인터넷에서 수집된 대량의 텍스트 데이터를 학습하여 텍스트를 생성하는 방법을 배웁니다. 이 텍스트는 다양한 주제와 스타일을 포함하여 모델이 언어의 다양성과 복잡성을 이해하는 데 도움이 됩니다.
학습 과정은 다음과 같습니다:
- 토큰화: 모델은 먼저 텍스트를 토큰으로 분리합니다. 토큰은 단어, 문장 부호, 또는 그 사이의 단위가 될 수 있습니다. 이 토큰화 과정은 언어에 따라 다르며, 때로는 하나의 단어를 여러 토큰으로 분리하기도 합니다.
- 순차적 학습: 모델은 그 다음으로 텍스트의 토큰을 순차적으로 학습합니다. 즉, 주어진 토큰을 바탕으로 다음 토큰이 무엇일지 예측하는 과정을 반복하며 학습합니다.
- 파라미터 조정: 모델은 학습 과정에서 예측이 얼마나 잘못되었는지를 평가하고, 이를 최소화하기 위해 내부 파라미터를 조정합니다. 이 과정을 수 백억 토큰에 걸쳐 반복함으로써, 모델은 문맥에 따라 텍스트를 생성하는 방법을 배웁니다.
이렇게 학습된 LLM은 주어진 프롬프트에 따라 문맥에 적합한 텍스트를 생성할 수 있게 됩니다. 이는 사용자의 질문에 답변하거나, 텍스트를 생성하거나, 문장을 완성하는 등 다양한 작업에 활용될 수 있습니다.

LLM 학습의 주요 도구는 실제로 지도 학습입니다.
지도 학습에서 컴퓨터는 레이블이 붙은 훈련 데이터를 사용하여 입력-출력 또는 X-Y 매핑을 배웁니다. 예를 들어, 지도 학습을 사용하여 레스토랑 리뷰의 감성을 분류하는 것을 배우려면, 다음과 같은 훈련 세트를 수집할 수 있습니다. “The pastrami sandwich is great!”와 같은 리뷰는 긍정적인 감정의 리뷰로 레이블이 붙여지고, “Service was slow, the food was so-so.”는 부정적이라고 레이블이 붙습니다. 그리고 “The earl grey tea was fantastic.”는 긍정적인 레이블이 붙습니다.
따라서 지도 학습의 과정은 일반적으로 레이블이 붙은 데이터를 얻고 AI 모델을 이 데이터로 훈련시키는 것입니다. 훈련 후에는 모델을 배포하고 호출하여 새로운 레스토랑 리뷰인 “best pizza I’ve ever had”와 같은 리뷰를 제공할 수 있습니다. 그럼 이 리뷰는 긍정적인 감정으로 출력될 것입니다.

구체적으로, 대규모 언어 모델은 지도 학습을 사용하여 반복적으로 다음 단어를 예측하는 방식으로 구축될 수 있습니다. 가령, 텍스트 데이터의 많은 학습 세트에서 “My favorite food is a bagel with cream cheese and lox.”라는 문장이 있을 때, 이 문장은 일련의 학습 예시로 변환됩니다.
문장의 일부인 “My favorite food is a”가 주어졌을 때 이 경우에 다음 단어를 예측하려면 “bagel”이어야 합니다. 또는 문장의 일부 또는 접두사인 “My favorite food is a bagel”이 주어졌을 때 이 경우에 다음 단어는 “with”가 됩니다.
수백억 개나 그 이상의 단어로 구성된 대규모 학습 세트를 가지고 있다면, 문장의 일부 또는 텍스트의 일부를 시작점으로 하여 언어 모델이 다음 단어가 무엇인지 반복적으로 학습하도록 요청하는 방대한 학습 세트를 생성할 수 있습니다. 이런 방식으로 언어 모델은 문맥에 맞는 다음 단어를 예측하는 능력을 향상시킵니다.

오늘날 대규모 언어 모델은 대략적으로 두 가지 주요 유형이 있습니다. 첫 번째는 “기본 LLM”이고 두 번째는 점점 더 많이 사용되는 “명령어 튜닝 LLM”입니다.
기본 LLM은 텍스트 훈련 데이터를 기반으로 다음 단어를 반복적으로 예측합니다. 그래서 “Once upon a time there was a unicorn”이라는 프롬프트를 제공하면, 한 번에 한 단어씩 반복적으로 예측하여 유니콘이 모든 유니콘 친구들과 함께 마법의 숲에서 살고 있는 이야기를 완성할 수 있습니다.
이 방법의 단점은 “What is the capital of France?”라는 프롬프트를 제공하면, 인터넷에서 프랑스에 대한 퀴즈 질문 목록이 있을 수 있으므로 이를 “프랑스의 가장 큰 도시는 무엇인가요, 프랑스의 인구는 얼마나 되나요?”등으로 완성할 수 있다는 것입니다. 그러나 실제로 원하는 것은 프랑스의 수도가 무엇인지를 알려주는 것일 것입니다.
이에 비해 명령어 튜닝 LLM은 명령을 따르려고 시도하므로 “프랑스의 수도는 파리입니다.”라고 답할 것입니다.

기본 LLM에서 명령어 튜닝 LLM으로 어떻게 바꿀 수 있을까요? 이는 ChatGPT와 같은 명령어 튜닝 LLM을 훈련하는 과정입니다.
먼저 많은 데이터(수백억 단어 이상)에 대해 기본 LLM을 훈련시킵니다. 이는 슈퍼컴퓨팅 시스템에서 수 개월이 걸릴 수 있습니다. 기본 LLM을 훈련시킨 후에는 출력이 입력 명령을 따르는 작은 예제 세트를 통해 모델을 더욱 미세 조정합니다. 예를 들어, 사람이 명령어와 그에 대한 좋은 응답의 예시를 많이 작성하는 것을 도와줄 수 있습니다.
이렇게 만들어진 학습 세트를 사용하여 추가적인 미세 조정을 수행하게 됩니다. 이 과정에서 언어 모델은 명령을 따르려고 할 때 다음 단어가 무엇인지 예측하도록 학습하게 됩니다. 그 후에는 LLM의 출력 품질을 향상시키기 위해, 많은 LLM 출력의 품질을 사람이 평가하는 것이 일반적인 과정이 됩니다. 이러한 평가는 출력이 유익하고, 정직하고, 해가 없는지와 같은 기준에 따라 이루어집니다.
그런 다음 LLM을 더욱 미세 조정하여, 더 높은 평가를 받은 출력을 생성할 확률을 높일 수 있습니다. 이를 수행하는 가장 일반적인 기술은 RLHF(인간의 피드백으로부터 강화학습)입니다. 기본 LLM의 훈련이 수개월이 걸리는 반면, 기본 LLM에서 명령어 튜닝 LLM으로 바꾸는 과정은 훨씬 작은 데이터 세트와 컴퓨팅 자원을 사용하여 몇 일 안에 이루어질 수 있습니다.

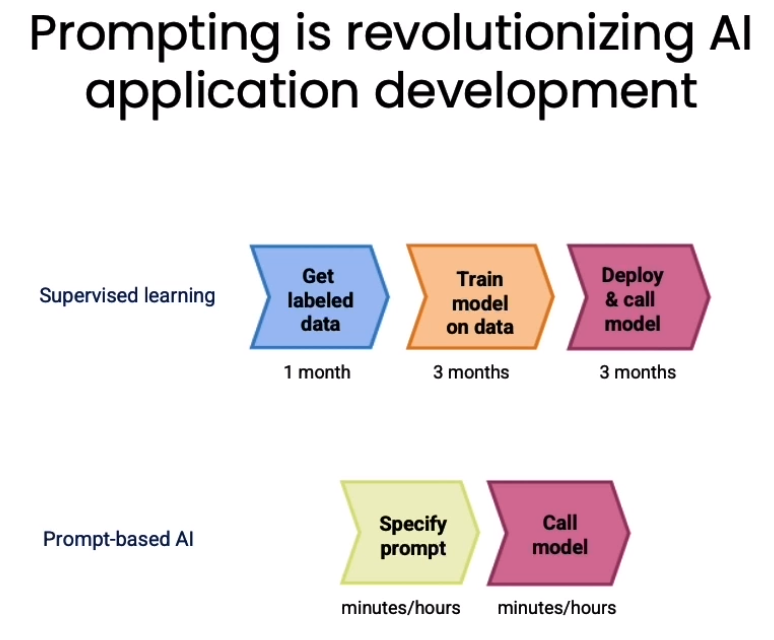
이 비디오에서는 인공지능 애플리케이션 개발에 있어서 ‘프롬프팅’이 어떻게 혁신적인 변화를 가져오고 있는지 설명하고 있습니다.
전통적인 지도학습 기반 머신러닝에서는 라벨이 붙은 많은 데이터를 수집하고, 그 데이터에 모델을 훈련시킨 후, 모델을 클라우드에 업로드하고 실행하는 등의 과정이 필요합니다. 이런 작업이 몇 달이 소요되는 것은 흔한 일입니다.
그러나 ‘프롬프팅’ 기반 머신러닝에서는 텍스트 애플리케이션의 경우, 몇 분에서 몇 시간 안에 프롬프트를 지정할 수 있습니다. 그리고 그 프롬프트를 API 호출로 실행하는 것이 가능하며, 이는 몇 시간, 최대 몇 일이 걸릴 수 있습니다. 그런 다음에는 몇 분에서 몇 시간 내에 모델을 호출하고 추론을 시작할 수 있습니다. 이처럼 ‘프롬프팅’을 이용하면 기존에는 6개월에서 1년이 걸렸던 작업들을 몇 분에서 몇 시간 안에 수행할 수 있게 되는 것입니다.
하지만 이 방식은 비구조화된 데이터, 특히 텍스트 또는 비전 데이터에 대한 애플리케이션에만 적용될 수 있습니다. 엑셀과 같은 구조화된 데이터에 대한 머신러닝 애플리케이션에는 이 방식이 잘 작동하지 않습니다.
그럼에도 불구하고, 이 방식이 적용 가능한 애플리케이션에서는, AI 구성 요소를 매우 빠르게 만들 수 있다는 것이 시스템 구축의 작업 흐름에 큰 변화를 가져오고 있습니다.




