과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



Cognita를 사용해야 하는 이유는 다음과 같습니다:
- 모듈화: Cognita는 Langchain/LlamaIndex를 기반으로 하지만, 각 RAG 컴포넌트를 모듈화하여 쉽게 확장하고 생산 환경에 적용할 수 있도록 합니다. 이를 통해 코드 베이스를 체계적으로 구성할 수 있습니다.
- 확장성: Cognita의 컴포넌트는 API 기반으로 구축되어 있어, 필요에 따라 쉽게 확장이 가능합니다. 이는 프로덕션 환경에서 중요한 요소입니다.
- 로컬 및 프로덕션 환경 지원: Cognita는 로컬 환경에서 쉽게 사용할 수 있을 뿐만 아니라, 프로덕션에 적합한 환경도 제공합니다. 이를 통해 개발과 배포 과정이 원활해집니다.
- No-code UI 지원: Cognita는 코딩 없이도 사용할 수 있는 사용자 인터페이스를 제공하여, 비개발자도 쉽게 시스템을 다룰 수 있습니다.
- 증분 인덱싱 지원: Cognita는 기본적으로 증분 인덱싱을 지원하므로, 데이터의 변화에 따라 효율적으로 인덱스를 업데이트할 수 있습니다.
즉, Cognita는 Langchain/LlamaIndex의 장점을 활용하면서도, 모듈화, 확장성, 프로덕션 환경 지원, No-code UI, 증분 인덱싱 등의 추가 기능을 제공하여 보다 실용적이고 효율적인 개발을 가능하게 합니다.
소개
Cognita는 RAG 코드베이스를 구성하고 다양한 RAG 커스터마이징을 시도해볼 수 있는 프론트엔드를 제공하는 오픈소스 프레임워크입니다. Cognita는 코드베이스를 간단하게 구성할 수 있는 방법을 제공하여, 로컬에서 쉽게 테스트하면서도 프로덕션 환경에 배포할 수 있도록 합니다. Jupyter Notebook에서 RAG 시스템을 프로덕션화하는 과정에서 발생하는 주요 이슈는 다음과 같습니다:
- 청킹 및 임베딩 작업: 청킹과 임베딩 코드는 보통 추상화되어 작업으로 배포되어야 합니다. 때로는 데이터를 최신 상태로 유지하기 위해 작업을 스케줄에 따라 실행하거나 이벤트에 의해 트리거되어야 합니다.
- 쿼리 서비스: 쿼리에서 답변을 생성하는 코드는 FastAPI와 같은 API 서버에 래핑되어 서비스로 배포되어야 합니다. 이 서비스는 동시에 여러 쿼리를 처리할 수 있어야 하며, 트래픽이 증가할 때 자동으로 확장될 수 있어야 합니다.
- LLM / 임베딩 모델 배포: 오픈소스 모델을 사용하는 경우, 주피터 노트북에서 모델을 로드하는 경우가 많습니다. 이는 프로덕션에서 별도의 서비스로 호스팅되어야 하며, 모델은 API로 호출되어야 합니다.
- 벡터 DB 배포: 대부분의 테스트는 메모리 또는 디스크의 벡터 DB에서 이루어집니다. 그러나 프로덕션에서는 DB를 보다 확장 가능하고 안정적인 방식으로 배포해야 합니다.
Cognita를 사용하면 RAG 시스템의 모든 것을 쉽게 커스터마이징하고 실험할 수 있으며, 동시에 적절한 방식으로 배포할 수 있습니다. 또한 다양한 RAG 구성을 시도하고 결과를 실시간으로 확인할 수 있는 UI도 제공합니다. Cognita는 로컬에서 사용할 수도 있고, Truefoundry 컴포넌트를 사용할 수 있습니다. 그러나 Truefoundry 컴포넌트를 사용하면 다양한 모델을 테스트하고 시스템을 확장 가능한 방식으로 배포하는 것이 더 쉬워집니다. Cognita를 사용하면 하나의 앱으로 여러 RAG 시스템을 호스팅할 수 있습니다.
Cognita를 사용하면 다음과 같은 이점이 있습니다:
- 파서, 로더, 임베더, 검색기 등의 중앙 재사용 가능한 저장소를 제공합니다.
- 비기술 사용자도 UI를 통해 시스템을 활용할 수 있습니다. 개발팀이 구축한 모듈을 사용하여 문서를 업로드하고 질의응답을 수행할 수 있습니다.
- 완전히 API 기반으로 동작하므로 다른 시스템과의 통합이 가능합니다.
Cognita를 Truefoundry AI Gateway와 함께 사용하면 사용자 쿼리에 대한 로깅, 메트릭, 피드백 메커니즘을 얻을 수 있습니다.
위의 장점을 통해 Cognita는 RAG 시스템 개발과 활용을 보다 효율적으로 만들어줍니다. 모듈화된 구조와 재사용 가능한 컴포넌트는 개발 생산성을 높이고, UI를 통해 비기술 사용자도 시스템을 쉽게 다룰 수 있게 합니다. 또한 API 기반 아키텍처는 다른 시스템과의 유연한 연동을 가능케 합니다.
특히 Truefoundry AI Gateway와의 통합은 사용자 쿼리에 대한 다양한 인사이트를 제공함으로써 시스템 개선에 도움을 줄 수 있습니다. 이를 통해 Cognita는 RAG 시스템 구축과 운영에 있어 강력한 프레임워크로 자리매김할 수 있을 것입니다.
주요 기능:
유사도 검색,쿼리 분해,문서 재순위화등을 사용하는 다양한 문서 검색기를 지원합니다.mixedbread-ai의 최신 오픈소스 임베딩과 재순위화 기술을 지원합니다.Ollama를 사용하여 LLM을 활용할 수 있습니다.- 전체 문서를 배치로 수집하는 증분 인덱싱을 지원하여 계산 부담을 줄이고, 이미 인덱싱된 문서를 추적하여 해당 문서의 재인덱싱을 방지합니다.
Cognita는 다양한 문서 검색 기술을 지원하여 사용자의 요구에 맞는 검색 방식을 선택할 수 있도록 합니다. 최신 오픈소스 기술을 활용할 수 있어 시스템의 성능을 높일 수 있습니다.
또한 Ollama를 통해 강력한 언어 모델을 사용할 수 있어 고품질의 자연어 처리가 가능합니다.
증분 인덱싱 기능은 대량의 문서를 효율적으로 처리할 수 있게 해주며, 이미 처리된 문서를 재처리하지 않아 불필요한 자원 낭비를 줄여줍니다.
이러한 기능들을 통해 Cognita는 다양한 RAG 시스템 구축 시나리오에 유연하게 대응할 수 있는 강력한 프레임워크가 될 것입니다. 사용자는 Cognita가 제공하는 다양한 모듈과 기능을 조합하여 자신만의 맞춤형 RAG 시스템을 손쉽게 구축할 수 있을 것입니다.
시작하기
Python 스크립트를 사용하거나 코드와 함께 제공되는 UI 컴포넌트를 사용하여 로컬에서 코드를 시험해볼 수 있습니다.
🐍 Python 설치 및 가상 환경 설정
Cognita를 사용하려면 시스템에 Python >=3.10.0이 설치되어 있고, 더 안전하고 깨끗한 프로젝트 설정을 위해 가상 환경을 만들 수 있어야 합니다.
가상 환경 설정
다른 프로젝트 또는 시스템 전체 Python 패키지와의 충돌을 피하기 위해 가상 환경을 사용하는 것이 좋습니다.
가상 환경 생성:
터미널에서 프로젝트 디렉토리로 이동합니다. 다음 명령을 실행하여 venv라는 이름의 가상 환경을 생성합니다(원하는 대로 이름을 지정할 수 있음):
python3 -m venv ./venv가상 환경 활성화:
- Windows에서는 다음을 실행하여 가상 환경을 활성화합니다:
venv\Scripts\activate.bat- macOS 및 Linux에서는 다음을 실행합니다:
source venv/bin/activate가상 환경이 활성화되면 터미널 프롬프트에 해당 이름이 표시됩니다. 이제 빠른 시작 섹션에 제공된 단계에 따라 Cognita를 설치할 준비가 되었습니다.
Cognita 작업을 마치면 터미널에서 간단히 deactivate를 실행하여 가상 환경을 비활성화하는 것을 잊지 마세요.
가상 환경을 사용하면 프로젝트별로 격리된 Python 환경을 구성할 수 있어 패키지 버전 충돌 등의 문제를 피할 수 있습니다. 또한 프로젝트에 필요한 패키지만 설치하므로 깔끔한 개발 환경을 유지할 수 있습니다.
Cognita 설치 전에 반드시 가상 환경을 생성하고 활성화하는 것이 좋습니다. 위의 명령어를 참고하여 가상 환경을 설정한 후 Cognita 설치를 진행하시기 바랍니다.
🚀 빠른 시작: Cognita를 로컬에서 실행하기
다음은 추가적인 Truefoundry 종속성 없이 Cognita를 로컬에서 실행하기 위한 지침입니다.
필요한 패키지 설치:
프로젝트 루트에서 다음 명령을 실행합니다:
pip install -r backend/requirements.txt.env 파일 설정:
env.local.example에서 복사하여.env파일을 생성하고 관련 필드를 설정합니다.
코드 실행:
- 프로젝트 루트에서 다음 명령을 실행하여 데이터(
sample-data/creditcards)를 인덱싱합니다:
python -m local.ingest- 쿼리를 실행하려면 프로젝트 루트에서 다음 명령을 실행합니다:
python -m local.run이러한 명령은
local.metadata.yaml파일을 사용하며, 여기서 qdrant 컬렉션 이름, 다양한 데이터 소스 경로 및 임베더 구성을 설정합니다.
run.py에서from backend.modules.query_controllers.example.payload로부터 다양한 검색기와 쿼리를 가져와 시도해볼 수 있습니다.FastAPI 서버를 시작할 수도 있습니다:
uvicorn --host 0.0.0.0 --port 8000 backend.server.app:app --reload그러면 Swagger 문서를http://localhost:8000/에서 사용할 수 있습니다. 로컬 버전에서는local.metadata.yaml과ingest.py파일에서 처리되므로 API를 사용하여 데이터 소스, 컬렉션 또는 인덱스를 생성할 필요가 없습니다. 직접 retrievers 엔드포인트를 시도해볼 수 있습니다.쿼리에 프론트엔드 UI를 사용하려면
cd fronend로 이동하여yarn dev를 실행하여 UI를 시작하고 사용해볼 수 있습니다. 자세한 내용은 프론트엔드 README를 참조하세요.
위의 지침에 따라 Cognita를 로컬 환경에서 실행하고 테스트해볼 수 있습니다. 먼저 필요한 패키지를 설치하고 설정 파일을 준비합니다. 그런 다음 제공된 명령을 사용하여 데이터를 인덱싱하고 쿼리를 실행할 수 있습니다.
다양한 검색기와 쿼리를 시험해보고 싶다면 run.py에서 해당 모듈을 가져와 사용할 수 있습니다. 또한 FastAPI 서버를 시작하여 API 엔드포인트를 통해 시스템을 테스트할 수도 있습니다.
프론트엔드 UI를 사용하려면 해당 디렉토리로 이동하여 별도로 실행한 후, 브라우저에서 UI를 통해 Cognita와 상호 작용할 수 있습니다.
이렇게 Cognita는 로컬 환경에서 쉽게 실행하고 테스트해볼 수 있는 유연한 프레임워크입니다.
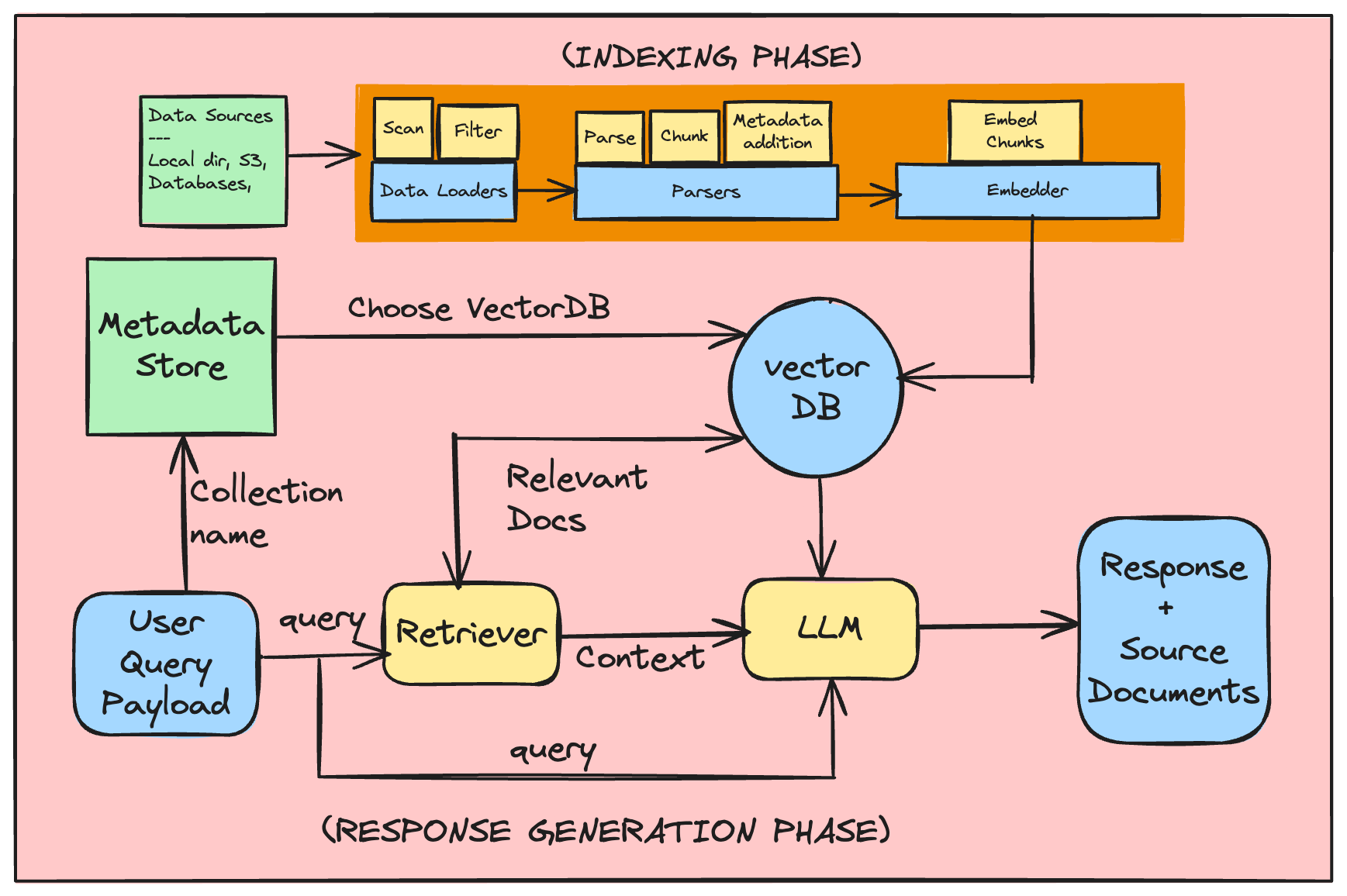
⚒️ Project Architecture

Cognita의 주요 구성 요소:
- 데이터 소스(Data Sources): 인덱싱할 문서가 포함된 위치입니다. 일반적으로 S3 버킷, 데이터베이스, TrueFoundry Artifacts 또는 로컬 디스크 등이 될 수 있습니다.
- 메타데이터 저장소(Metadata Store): 컬렉션 자체에 대한 메타데이터를 포함하는 저장소입니다. 컬렉션은 하나 이상의 데이터 소스에서 결합된 문서 집합을 의미합니다. 각 컬렉션에 대해 컬렉션 메타데이터는 다음을 저장합니다:
- 컬렉션 이름
- 연결된 벡터 DB 컬렉션 이름
- 연결된 데이터 소스
- 각 데이터 소스에 대한 파싱 설정
- 사용할 임베딩 모델 및 구성
- LLM 게이트웨이(LLM Gateway): 다양한 임베딩 및 LLM 모델에 대한 요청을 통합된 API 형식으로 프록시할 수 있는 중앙 프록시입니다. OpenAIChat, OllamaChat 또는 TF LLM Gateway를 사용하는 TruefoundryChat이 될 수 있습니다.
- 벡터 DB(Vector DB): 파싱된 파일의 임베딩과 메타데이터를 저장합니다. 유사한 청크를 얻거나 필터를 기반으로 정확한 일치를 쿼리할 수 있습니다. 현재 벡터 데이터베이스로
Qdrant와SingleStore를 지원하고 있습니다. - 인덱싱 작업(Indexing Job): 인덱싱 흐름을 조정하는 비동기 작업입니다. 인덱싱은 수동으로 시작하거나 크론 일정에 따라 정기적으로 실행할 수 있습니다. 다음을 수행합니다:
- 데이터 소스를 스캔하여 문서 목록 가져오기
- 벡터 DB 상태를 확인하여 변경되지 않은 문서 필터링
- 파일을 다운로드하고 파싱하여 연관된 메타데이터와 함께 더 작은 청크 생성
- AI 게이트웨이를 사용하여 청크를 임베딩하고 벡터 DB에 저장
> 이에 대한 소스 코드는backend/indexer/에 있습니다.
- API 서버(API Server): 이 구성 요소는 사용자 쿼리를 처리하여 동기적으로 참조와 함께 답변을 생성합니다. 각 애플리케이션은 검색 및 응답 프로세스를 완전히 제어할 수 있습니다. 사용자가 요청을 보내면 대략적으로 다음과 같은 일이 발생합니다:
- 해당 쿼리 컨트롤러가 구성에 따라 검색기 또는 다단계 에이전트를 부트스트랩합니다.
- 사용자의 질문이 처리되고 AI 게이트웨이를 사용하여 임베딩됩니다.
- 하나 이상의 검색기가 벡터 DB와 상호 작용하여 관련 청크와 메타데이터를 가져옵니다.
- AI 게이트웨이를 통해 LLM을 사용하여 최종 답변이 형성됩니다.
- 프로세스 중에 가져온 관련 문서의 메타데이터를 선택적으로 보강할 수 있습니다. 예를 들어 사전 서명된 URL 추가 등이 있습니다.
> 이 구성 요소의 코드는backend/server/에 있습니다.
데이터 인덱싱:
- 특정 일정에 따라 크론(Cron)이 인덱싱 작업을 트리거합니다.
- 컬렉션과 연결된 데이터 소스가 모든 데이터 포인트(파일)에 대해 스캔됩니다.
- 작업은 벡터DB 상태와 데이터 소스 상태를 비교하여 새로 추가된 파일, 업데이트된 파일, 삭제된 파일을 파악합니다. 새 파일과 업데이트된 파일은 다운로드됩니다.
- 새로 추가된 파일과 업데이트된 파일은 각각 고유한 메타데이터를 가진 더 작은 조각으로 파싱 및 분할(chunked)됩니다.
- 청크는
openai의text-ada-002나mixedbread-ai의mxbai-embed-large-v1과 같은 임베딩 모델을 사용하여 임베딩됩니다. - 임베딩된 청크는 자동 생성된 메타데이터와 제공된 메타데이터와 함께 벡터DB에 저장됩니다.
이 프로세스를 통해 Cognita는 데이터 소스의 변경 사항을 효율적으로 추적하고 새로운 데이터를 인덱싱할 수 있습니다. 크론 작업을 통해 주기적으로 데이터 소스를 스캔하고, 변경된 파일만 선택적으로 처리함으로써 불필요한 작업을 최소화합니다.
파일은 더 작은 청크로 분할되어 임베딩되고, 메타데이터와 함께 벡터DB에 저장됩니다. 이렇게 저장된 데이터는 검색 및 질의 응답 시 효율적으로 활용될 수 있습니다.
Cognita의 데이터 인덱싱 프로세스는 대용량 데이터를 다룰 때 특히 유용합니다. 증분 인덱싱을 통해 변경된 부분만 처리하므로 시간과 자원을 절약할 수 있습니다. 또한 모듈화된 구조 덕분에 다양한 데이터 소스와 임베딩 모델을 유연하게 활용할 수 있습니다.
❓ API 서버를 사용한 질의 응답:
- 사용자가 쿼리와 함께 요청을 보냅니다.
- 요청은 앱의 쿼리 컨트롤러 중 하나로 라우팅됩니다.
- 벡터 DB 위에 하나 이상의 검색기(retriever)가 구성됩니다.
- 그런 다음 질의 응답 체인/에이전트가 구성됩니다. 사용자 쿼리를 임베딩하고 유사한 청크를 가져옵니다.
- 단일 샷 질의 응답 체인은 유사한 청크가 주어지면 답변을 생성합니다. 에이전트는 답변에 도달하기 전에 다단계 추론을 수행하고 많은 도구를 사용할 수 있습니다. 두 경우 모두 API 서버는 GPT 3.5, GPT 4 등과 같은 LLM 모델을 사용합니다.
- 답변을 반환하기 전에 관련 청크의 메타데이터를 사전 서명된 URL, 주변 슬라이드, 외부 데이터 소스 링크 등으로 업데이트할 수 있습니다.
- 답변과 관련 문서 청크가 응답으로 반환됩니다. 참고: 에이전트의 경우 중간 단계도 스트리밍될 수 있습니다. 특정 앱에 따라 결정됩니다.
이 프로세스는 사용자 쿼리에 대한 관련성 높은 답변을 효율적으로 생성하는 방법을 보여줍니다. 사용자 요청은 적절한 쿼리 컨트롤러로 라우팅되고, 벡터 DB를 기반으로 검색기가 구성됩니다.
그런 다음 질의 응답 체인 또는 에이전트가 사용자 쿼리를 임베딩하고 유사한 청크를 검색합니다. 단일 샷 체인은 검색된 청크를 바탕으로 답변을 생성하는 반면, 에이전트는 다단계 추론과 다양한 도구를 사용하여 답변을 도출할 수 있습니다.
답변 반환 전에 관련 청크의 메타데이터를 보강하여 사용자에게 더 풍부한 정보를 제공할 수 있습니다. 최종적으로 생성된 답변과 관련 문서 청크가 사용자에게 전달됩니다.
Cognita의 API 서버는 이러한 유연한 질의 응답 프로세스를 통해 사용자의 다양한 요구사항에 효과적으로 대응할 수 있습니다.
사용 사례에 맞게 코드 사용자 정의하기
Cognita의 슬로건은 다음과 같습니다.
모든 것이 가능하고 모든 것이 사용자 정의 가능합니다.
Cognita는 파서, 로더, 모델 및 검색기 간의 전환을 매우 쉽게 만듭니다.
데이터 소스 및 로더 사용자 정의
Cognita는 다양한 데이터 소스와 로더를 지원합니다. S3, 로컬 파일 시스템, 데이터베이스 등 다양한 소스의 데이터를 쉽게 통합할 수 있습니다. backend/modules/data_source/에서 새로운 데이터 소스와 로더를 구현하거나 기존 구현을 수정할 수 있습니다.
파서 사용자 정의
파서는 원시 데이터를 청크와 메타데이터로 변환하는 역할을 합니다. Cognita는 여러 유형의 파일(텍스트, PDF, 이미지 등)에 대한 기본 파서를 제공합니다. backend/modules/parser/에서 새로운 파서를 추가하거나 기존 파서를 수정할 수 있습니다.
임베더 및 LLM 사용자 정의
Cognita의 LLM 게이트웨이를 통해 다양한 임베딩 모델과 LLM을 사용할 수 있습니다. OpenAI, Hugging Face, TrueFoundry 등의 모델을 지원합니다. backend/modules/llms/에서 새로운 LLM 프로바이더를 추가하거나 기존 구현을 수정할 수 있습니다.
검색기 및 체인 사용자 정의
검색기는 사용자 쿼리를 기반으로 관련 청크를 검색하는 역할을 합니다. Cognita는 다양한 유사도 검색 알고리즘과 쿼리 분해 기술을 지원합니다. backend/modules/retrievers/에서 새로운 검색기를 구현하거나 기존 검색기를 수정할 수 있습니다.
또한 backend/modules/query_controllers/에서 다양한 질의 응답 체인과 에이전트를 사용자 정의할 수 있습니다. 단일 샷 응답, 다단계 추론, 도구 사용 등 다양한 전략을 구현할 수 있습니다.
벡터 DB 사용자 정의
Cognita는 Qdrant, SingleStore 등 다양한 벡터 DB를 지원합니다. backend/modules/vectordb/에서 새로운 벡터 DB 연동을 추가하거나 기존 구현을 수정할 수 있습니다.
Cognita의 모듈화된 아키텍처 덕분에 코드베이스의 특정 부분을 쉽게 사용자 정의하고 확장할 수 있습니다. 필요에 따라 데이터 소스, 파서, 임베더, 검색기, 질의 응답 체인 등을 유연하게 조정하여 사용 사례에 맞게 최적화된 시스템을 구축할 수 있습니다.
데이터 로더 사용자 정의하기:
backend/modules/dataloaders/loader.py에서BaseDataLoader클래스를 상속받아 자신만의 데이터 로더를 작성할 수 있습니다.- 마지막으로
backend/modules/dataloaders/__init__.py에 로더를 등록합니다. - 로컬 디렉토리에서 데이터 로더를 테스트하려면 루트 디렉토리에 다음 코드를
test.py로 복사하고 실행하세요. 여기서는 기존LocalDirLoader를 테스트하는 방법을 보여줍니다:
from backend.modules.dataloaders import LocalDirLoader
from backend.types import DataSource
data_source = DataSource(
type="local",
uri="sample-data/creditcards",
)
loader = LocalDirLoader()
loaded_data_pts = loader.load_full_data(
data_source=data_source,
dest_dir="test/creditcards",
)
for data_pt in loaded_data_pts:
print(data_pt)위의 예시는 LocalDirLoader를 사용하여 로컬 디렉토리에서 데이터를 로드하는 방법을 보여줍니다. DataSource 객체를 생성하여 데이터 소스의 유형과 경로를 지정합니다.
그런 다음 LocalDirLoader 인스턴스를 생성하고 load_full_data 메서드를 호출하여 데이터를 로드합니다. 로드된 데이터 포인트는 loaded_data_pts 리스트에 저장되며, 이를 반복하여 각 데이터 포인트를 출력할 수 있습니다.
새로운 데이터 로더를 구현할 때는 BaseDataLoader 클래스를 상속받고 필요한 메서드를 오버라이드합니다. 로더의 load_full_data 메서드는 데이터 소스에서 데이터를 로드하고 데이터 포인트 리스트를 반환해야 합니다.
구현한 데이터 로더를 backend/modules/dataloaders/__init__.py에 등록하는 것을 잊지 마세요. 그러면 Cognita의 다른 부분에서 해당 로더를 사용할 수 있습니다.
위의 예시 코드를 참고하여 다양한 데이터 소스에 대한 로더를 작성하고 테스트할 수 있습니다. 이를 통해 Cognita를 사용자 정의하고 확장하여 다양한 데이터 소스를 원활하게 통합할 수 있습니다.
임베더 사용자 정의하기:
- 현재 코드베이스는
default로 등록된OpenAIEmbeddings를 사용합니다. backend/modules/embedder/__init__.py에서 사용자 정의 임베딩을 등록할 수 있습니다.backend/modules/embedder/mixbread_embedder.py에 제공된 예제와 같이 자신만의 임베더를 추가할 수도 있습니다. 이 예제는 Langchain의 임베딩 클래스를 상속받습니다.
임베더를 사용자 정의하려면 다음 단계를 따르세요:
backend/modules/embedder/디렉토리에 새로운 임베더 클래스를 작성합니다. 예를 들어custom_embedder.py라는 파일을 생성할 수 있습니다.- 새로운 임베더 클래스에서 Langchain의
Embeddings클래스를 상속받습니다. 필요한 메서드를 오버라이드하고 구현합니다.
from langchain.embeddings.base import Embeddings
class CustomEmbedder(Embeddings):
def embed_documents(self, texts: List[str]) -> List[List[float]]:
# 텍스트 리스트를 임베딩하는 로직 구현
pass
def embed_query(self, text: str) -> List[float]:
# 단일 쿼리를 임베딩하는 로직 구현
passbackend/modules/embedder/__init__.py파일에서 새로운 임베더를 임포트하고 등록합니다.
from backend.modules.embedder.custom_embedder import CustomEmbedder
EMBEDDER_REGISTRY = {
"default": OpenAIEmbeddings,
"custom": CustomEmbedder,
}- 이제
local.metadata.yaml이나 기타 설정 파일에서custom임베더를 사용할 수 있습니다.
embedder_config:
provider: custom
config:
# 필요한 설정 옵션 지정위의 단계를 따라 Cognita에 사용자 정의 임베더를 통합할 수 있습니다. 사용자 정의 임베더를 구현할 때는 Langchain의 Embeddings 클래스에 정의된 인터페이스를 준수해야 합니다.
embed_documents 메서드는 텍스트 리스트를 임베딩하고 임베딩 벡터 리스트를 반환해야 합니다. embed_query 메서드는 단일 쿼리를 임베딩하고 해당 벡터를 반환해야 합니다.
사용자 정의 임베더를 등록한 후에는 설정 파일에서 해당 임베더를 선택하여 사용할 수 있습니다. 이를 통해 Cognita에서 다양한 임베딩 모델과 기술을 유연하게 활용할 수 있습니다.
파서 사용자 정의하기:
backend/modules/parsers/parser.py에서BaseParser클래스를 상속받아 자신만의 파서를 작성할 수 있습니다.- 마지막으로
backend/modules/parsers/__init__.py에 파서를 등록합니다. - 로컬 파일에서 파서를 테스트하려면 루트 디렉토리에 다음 코드를
test.py로 복사하고 실행하세요. 여기서는 기존MarkdownParser를 테스트하는 방법을 보여줍니다:
import asyncio
from backend.modules.parsers import MarkdownParser
parser = MarkdownParser()
chunks = asyncio.run(
parser.get_chunks(
filepath="sample-data/creditcards/diners-club-black.md",
)
)
print(chunks)파서를 사용자 정의하려면 다음 단계를 따르세요:
backend/modules/parsers/디렉토리에 새로운 파서 클래스를 작성합니다. 예를 들어custom_parser.py라는 파일을 생성할 수 있습니다.- 새로운 파서 클래스에서
BaseParser클래스를 상속받습니다.get_chunks메서드를 오버라이드하고 구현합니다.
from backend.modules.parsers.parser import BaseParser, Chunk
class CustomParser(BaseParser):
async def get_chunks(self, filepath: str) -> List[Chunk]:
# 파일을 청크로 파싱하는 로직 구현
passbackend/modules/parsers/__init__.py파일에서 새로운 파서를 임포트하고 등록합니다.
from backend.modules.parsers.custom_parser import CustomParser
PARSER_REGISTRY = {
"default": MarkdownParser,
"custom": CustomParser,
}- 이제
local.metadata.yaml이나 기타 설정 파일에서custom파서를 사용할 수 있습니다.
parser_config:
provider: custom
config:
# 필요한 설정 옵션 지정위의 단계를 따라 Cognita에 사용자 정의 파서를 통합할 수 있습니다. 사용자 정의 파서를 구현할 때는 BaseParser 클래스에 정의된 인터페이스를 준수해야 합니다.
get_chunks 메서드는 파일 경로를 받아 해당 파일을 청크 리스트로 파싱해야 합니다. 청크는 Chunk 클래스의 인스턴스로 반환되어야 합니다.
사용자 정의 파서를 등록한 후에는 설정 파일에서 해당 파서를 선택하여 사용할 수 있습니다. 이를 통해 Cognita에서 다양한 파일 형식과 구조를 처리할 수 있는 유연성을 확보할 수 있습니다.
제공된 예시 코드를 참고하여 로컬 파일에서 파서를 테스트할 수 있습니다. asyncio.run을 사용하여 비동기 함수인 get_chunks를 실행하고 결과를 출력합니다.
사용자 정의 VectorDB 추가하기:
- VectorDB에 대한 자신만의 인터페이스를 추가하려면
backend/modules/vector_db/base.py에서BaseVectorDB를 상속받을 수 있습니다. backend/modules/vector_db/__init__.py에서 벡터 DB를 등록합니다.
사용자 정의 VectorDB를 추가하려면 다음 단계를 따르세요:
backend/modules/vector_db/디렉토리에 새로운 벡터 DB 클래스를 작성합니다. 예를 들어custom_vectordb.py라는 파일을 생성할 수 있습니다.- 새로운 벡터 DB 클래스에서
BaseVectorDB클래스를 상속받습니다. 필요한 메서드를 오버라이드하고 구현합니다.
from backend.modules.vector_db.base import BaseVectorDB
from backend.modules.vector_db.types import MetaData, DocChunk
class CustomVectorDB(BaseVectorDB):
def add_texts(self, texts: List[str], metadatas: Optional[List[MetaData]] = None):
# 텍스트와 메타데이터를 벡터 DB에 추가하는 로직 구현
pass
def add_chunks(self, chunks: List[DocChunk]):
# 청크 리스트를 벡터 DB에 추가하는 로직 구현
pass
def delete(self, doc_id: str, **kwargs):
# 문서를 벡터 DB에서 삭제하는 로직 구현
pass
def delete_by_filter(self, filter: Dict[str, str], **kwargs):
# 필터 조건에 맞는 문서를 벡터 DB에서 삭제하는 로직 구현
pass
def get_relevant_chunks(self, query: str, limit: int) -> List[DocChunk]:
# 쿼리와 관련된 청크를 벡터 DB에서 가져오는 로직 구현
passbackend/modules/vector_db/__init__.py파일에서 새로운 벡터 DB를 임포트하고 등록합니다.
from backend.modules.vector_db.custom_vectordb import CustomVectorDB
VECTOR_DB_REGISTRY = {
"default": QdrantClient,
"custom": CustomVectorDB,
}- 이제
local.metadata.yaml이나 기타 설정 파일에서custom벡터 DB를 사용할 수 있습니다.
vector_db_config:
provider: custom
config:
# 필요한 설정 옵션 지정위의 단계를 따라 Cognita에 사용자 정의 벡터 DB를 통합할 수 있습니다. 사용자 정의 벡터 DB를 구현할 때는 BaseVectorDB 클래스에 정의된 인터페이스를 준수해야 합니다.
각 메서드는 벡터 DB와의 상호 작용을 담당합니다. add_texts는 텍스트와 메타데이터를 추가하고, add_chunks는 청크 리스트를 추가합니다. delete는 문서를 삭제하고, delete_by_filter는 필터 조건에 맞는 문서를 삭제합니다. get_relevant_chunks는 쿼리와 관련된 청크를 가져옵니다.
사용자 정의 벡터 DB를 등록한 후에는 설정 파일에서 해당 벡터 DB를 선택하여 사용할 수 있습니다. 이를 통해 Cognita에서 다양한 벡터 DB를 유연하게 활용할 수 있습니다.
재순위 모델(Rerankers):
- 재순위 모델은 관련 문서를 정렬하여 상위 k개 문서를 컨텍스트로 효과적으로 사용할 수 있도록 하여 전반적으로 컨텍스트와 프롬프트를 줄이는 데 사용됩니다.
- 샘플 재순위 모델은
backend/modules/reranker/mxbai_reranker.py에 작성되어 있습니다.
재순위 모델은 검색 결과의 순위를 조정하여 가장 관련성 높은 문서를 상위에 배치하는 역할을 합니다. 이를 통해 상위 k개의 문서만 선택하여 컨텍스트로 사용할 수 있으므로 컨텍스트와 프롬프트의 크기를 줄일 수 있습니다.
재순위 모델을 구현하려면 다음 단계를 따르세요:
backend/modules/reranker/디렉토리에 새로운 재순위 모델 클래스를 작성합니다. 예를 들어custom_reranker.py라는 파일을 생성할 수 있습니다.- 새로운 재순위 모델 클래스에서
BaseReRanker클래스를 상속받습니다.rerank메서드를 오버라이드하고 구현합니다.
from backend.modules.reranker.base import BaseReRanker
from backend.modules.vector_db.types import DocumentChunk
class CustomReRanker(BaseReRanker):
def rerank(self, query: str, docs: List[DocumentChunk], top_n: int) -> List[DocumentChunk]:
# 주어진 문서를 재순위화하여 상위 top_n개 문서를 반환하는 로직 구현
passbackend/modules/reranker/__init__.py파일에서 새로운 재순위 모델을 임포트하고 등록합니다.
from backend.modules.reranker.custom_reranker import CustomReRanker
RERANKER_REGISTRY = {
"default": MxBaiReRanker,
"custom": CustomReRanker,
}- 이제
local.metadata.yaml이나 기타 설정 파일에서custom재순위 모델을 사용할 수 있습니다.
reranker_config:
provider: custom
config:
# 필요한 설정 옵션 지정위의 단계를 따라 Cognita에 사용자 정의 재순위 모델을 통합할 수 있습니다. 사용자 정의 재순위 모델을 구현할 때는 BaseReRanker 클래스에 정의된 인터페이스를 준수해야 합니다.
rerank 메서드는 쿼리, 문서 목록, 상위 개수(top_n)를 받아 재순위화된 상위 문서 목록을 반환해야 합니다. 재순위화 로직은 모델의 특성에 따라 다양하게 구현될 수 있습니다.
사용자 정의 재순위 모델을 등록한 후에는 설정 파일에서 해당 모델을 선택하여 사용할 수 있습니다. 이를 통해 Cognita에서 다양한 재순위화 전략을 유연하게 적용할 수 있습니다.
backend/modules/reranker/mxbai_reranker.py에 작성된 샘플 재순위 모델을 참고하여 자신만의 재순위 모델을 구현할 수 있습니다.
💡 쿼리 컨트롤러 작성하기 (QnA):
RAG 애플리케이션의 쿼리 인터페이스를 구현하는 코드입니다. 이러한 쿼리 컨트롤러에 정의된 메서드는 FastAPI 서버에 라우트로 추가됩니다.
사용자 정의 쿼리 컨트롤러를 추가하는 단계:
backend/modules/query_controllers/에 쿼리 컨트롤러 클래스를 추가합니다.- 클래스에
query_controller데코레이터를 추가하고 사용자 정의 컨트롤러의 이름을 인수로 전달합니다.
from backend.server.decorator import query_controller
@query_controller("/my-controller")
class MyCustomController():
...- 필요에 따라 컨트롤러에 메서드를 추가하고
post, get, delete와 같은 HTTP 데코레이터를 사용하여 메서드를 API로 만듭니다.
from backend.server.decorator import post
@query_controller("/my-controller")
class MyCustomController():
...
@post("/answer")
def answer(query: str):
# 답변에 대한 로직을 표현하는 코드 작성
# 이 API는 POST /my-controller/answer로 노출됩니다.
...backend/modules/query_controllers/__init__.py에서 사용자 정의 컨트롤러 클래스를 임포트합니다.
...
from backend.modules.query_controllers.sample_controller.controller import MyCustomController예시로
backend/modules/query_controllers/example에 샘플 컨트롤러를 구현해 두었습니다. 이해를 돕기 위해 참조하시기 바랍니다.
위의 단계에 따라 Cognita에 사용자 정의 쿼리 컨트롤러를 추가할 수 있습니다. 쿼리 컨트롤러는 RAG 애플리케이션의 쿼리 처리 로직을 담당합니다.
query_controller 데코레이터를 사용하여 클래스를 쿼리 컨트롤러로 지정하고, 해당 컨트롤러의 엔드포인트를 정의합니다.
컨트롤러 내부에는 다양한 메서드를 정의할 수 있습니다. 각 메서드는 post, get, delete와 같은 HTTP 데코레이터를 사용하여 API 엔드포인트로 노출됩니다. 메서드 내부에는 쿼리 처리 로직을 구현합니다.
사용자 정의 쿼리 컨트롤러를 구현한 후에는 backend/modules/query_controllers/__init__.py에서 해당 컨트롤러를 임포트해야 합니다. 그러면 FastAPI 서버에서 해당 컨트롤러의 엔드포인트를 라우팅할 수 있습니다.
backend/modules/query_controllers/example에 제공된 샘플 컨트롤러를 참고하여 자신만의 쿼리 컨트롤러를 작성할 수 있습니다. 샘플 컨트롤러는 쿼리 컨트롤러 구현의 예시를 보여주며, 이를 바탕으로 필요에 맞게 커스터마이징할 수 있습니다.
RAG UI 사용하기:
다음 단계는 Cognita UI를 사용하여 문서를 쿼리하는 방법을 보여줍니다:
- 데이터 소스 생성
Data Sources탭을 클릭합니다.+ New Datasource를 클릭합니다.- 데이터 소스 유형은 로컬 디렉토리의 파일, 웹 URL, GitHub URL 또는 Truefoundry 아티팩트 FQN을 제공하는 것일 수 있습니다.
- 예:
Localdir을 선택한 경우 머신에서 파일을 업로드하고Submit을 클릭합니다.
- 예:
- 생성된 데이터 소스 목록은 Data Sources 탭에서 확인할 수 있습니다.
- 컬렉션 생성
Collections탭을 클릭합니다.+ New Collection을 클릭합니다.- 컬렉션 이름을 입력합니다.
- 임베딩 모델을 선택합니다.
- 앞서 생성한 데이터 소스와 필요한 구성을 추가합니다.
Process를 클릭하여 컬렉션을 생성하고 데이터를 인덱싱합니다.
- 컬렉션을 생성하는 즉시 데이터 수집이 시작됩니다. Collections 탭에서 컬렉션을 선택하여 상태를 확인할 수 있습니다. 나중에 추가 데이터 소스를 추가하고 컬렉션에 인덱싱할 수도 있습니다.
- 응답 생성
- 컬렉션을 선택합니다.
- LLM과 해당 구성을 선택합니다.
- 문서 검색기를 선택합니다.
- 프롬프트를 작성하거나 기본 프롬프트를 사용합니다.
- 쿼리를 입력합니다.
위의 단계를 따라 Cognita UI를 통해 문서를 쿼리할 수 있습니다. 먼저 데이터 소스를 생성하여 쿼리할 문서를 제공합니다. 로컬 디렉토리, 웹 URL, GitHub URL 또는 Truefoundry 아티팩트 등 다양한 소스를 사용할 수 있습니다.
그런 다음 컬렉션을 생성하고 필요한 구성을 설정합니다. 컬렉션 이름, 임베딩 모델, 데이터 소스 등을 지정합니다. 컬렉션 생성 시 데이터 수집과 인덱싱이 자동으로 시작됩니다.
컬렉션이 준비되면 LLM, 문서 검색기, 프롬프트 등을 선택하고 쿼리를 입력하여 응답을 생성할 수 있습니다. UI를 통해 직관적으로 RAG 시스템을 구성하고 문서를 쿼리할 수 있습니다.
Cognita UI는 RAG 시스템의 다양한 구성 요소를 쉽게 관리하고 사용할 수 있도록 도와줍니다. 데이터 소스 관리, 컬렉션 생성, 쿼리 입력 등의 과정을 간편하게 수행할 수 있습니다. 이를 통해 개발자와 사용자 모두 RAG 시스템을 효과적으로 활용할 수 있습니다.