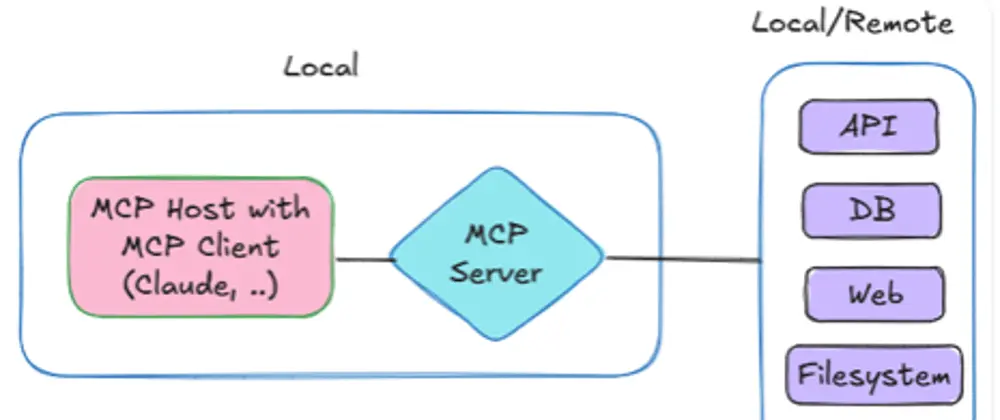
기반의 문서 처리 시스템 구축")


n8n은 다양한 애플리케이션 및 서비스와 원활하게 통합할 수 있도록 지원합니다. 하지만 특정 애플리케이션에 대한 전용 노드가 없더라도 HTTP 요청 (HTTP Request) 노드를 사용하여 해당 서비스와 연결할 수 있습니다. 이를 통해 사용자는 원하는 API 엔드포인트를 호출하고 데이터를 활용할 수 있습니다.
HTTP 요청 노드가 필요한 이유
HTTP 요청 노드는 다음과 같은 경우에 특히 유용합니다:
- n8n에서 기본적으로 지원하지 않는 앱 및 서비스와 연결할 때
- 웹 스크래핑(Web Scraping)으로 데이터를 추출할 때
- API 페이지네이션(Pagination)을 처리하여 대량의 데이터를 가져올 때
워크플로우 작동 방식
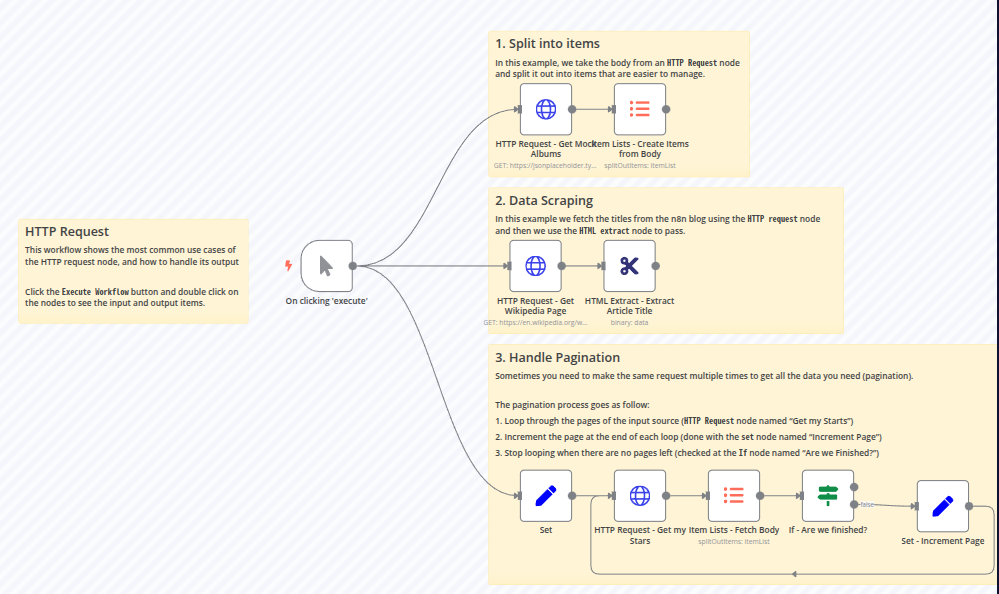
n8n에서 HTTP 요청 노드를 활용한 워크플로우는 세 개의 주요 분기로 나뉘며, 각 분기는 특정한 기능을 수행합니다.
1. 데이터를 개별 항목으로 분할하기
(HTTP Request – Get Mock Albums)
- 워크플로우는 **수동 실행 트리거(On clicking ‘execute’)**로 시작됩니다.
https://jsonplaceholder.typicode.com/albums에 HTTP 요청을 보내 모의 앨범 데이터를 가져옵니다.- 받은 JSON 데이터를 Item Lists 노드를 사용하여 개별 항목으로 분할합니다.
2. HTTP 요청을 활용한 웹 스크래핑
(HTTP Request – Get Wikipedia Page & HTML Extract)
- 이 분기에서는
https://en.wikipedia.org/wiki/Special:Random을 호출하여 랜덤 위키백과 페이지를 가져옵니다. - 받은 HTML 데이터에서 HTML Extract 노드를 사용하여 기사 제목을 추출합니다.
- 이 방법은 특정 웹사이트에서 자동으로 데이터를 추출할 때 유용합니다.
3. API 페이지네이션 처리하기
(HTTP Request – Fetch Starred GitHub Repositories)
- 이 분기는 API 페이지네이션 처리를 담당하며, 대량의 데이터를 여러 페이지에 걸쳐 가져오는 기능을 구현합니다.
- 작동 방식:
https://api.github.com/users/that-one-tom/starred에 대한 HTTP 요청을 보냅니다.- Set 노드를 사용하여
page번호 및items per page값을 설정합니다. - If 노드(“Are we finished?”)를 사용하여 더 가져올 페이지가 있는지 확인합니다.
- 남은 페이지가 있다면 Set – Increment Page 노드에서
page값을 증가시키고, 모든 데이터를 가져올 때까지 요청을 반복합니다.
결론
n8n의 HTTP 요청 노드는 외부 API와 상호 작용할 수 있는 매우 강력한 도구입니다.
- 특정 애플리케이션과 연동할 수 있는 전용 노드가 없더라도 API 요청을 통해 데이터를 가져오고 활용할 수 있습니다.
- 웹 스크래핑을 활용하여 원하는 정보를 자동으로 추출할 수 있습니다.
- API 페이지네이션을 처리하여 대량의 데이터를 손쉽게 수집할 수 있습니다.
이 워크플로우를 참고하여 n8n에서 더욱 강력한 자동화 시스템을 구축해보세요!