모델이 다음 단어 생성에 대한 최종 결정을 내리는 방식에 영향을 미치는 방법과 관련 구성 매개변수들을 살펴보겠습니다. Hugging Face 웹사이트나 AWS에서 LLM을 사용해 보셨다면, LLM이 어떻게 작동하는지 조정할 수 있는 이러한 컨트롤들을 접해 보셨을 것입니다. 각 모델은 추론 중에 모델의 출력에 영향을 미칠 수 있는 일련의 구성 매개변수를 제공합니다. 이것들은 학습 시간 동안 학습되는 학습 매개변수와는 다른 것들이라는 점을 주목하세요. 대신, 이 구성 매개변수들은 추론 시간에 호출되어 완성 작업에서의 토큰 최대 수와 출력의 창조성과 같은 것들을 제어하는 데 있어 여러분에게 권한을 부여합니다.

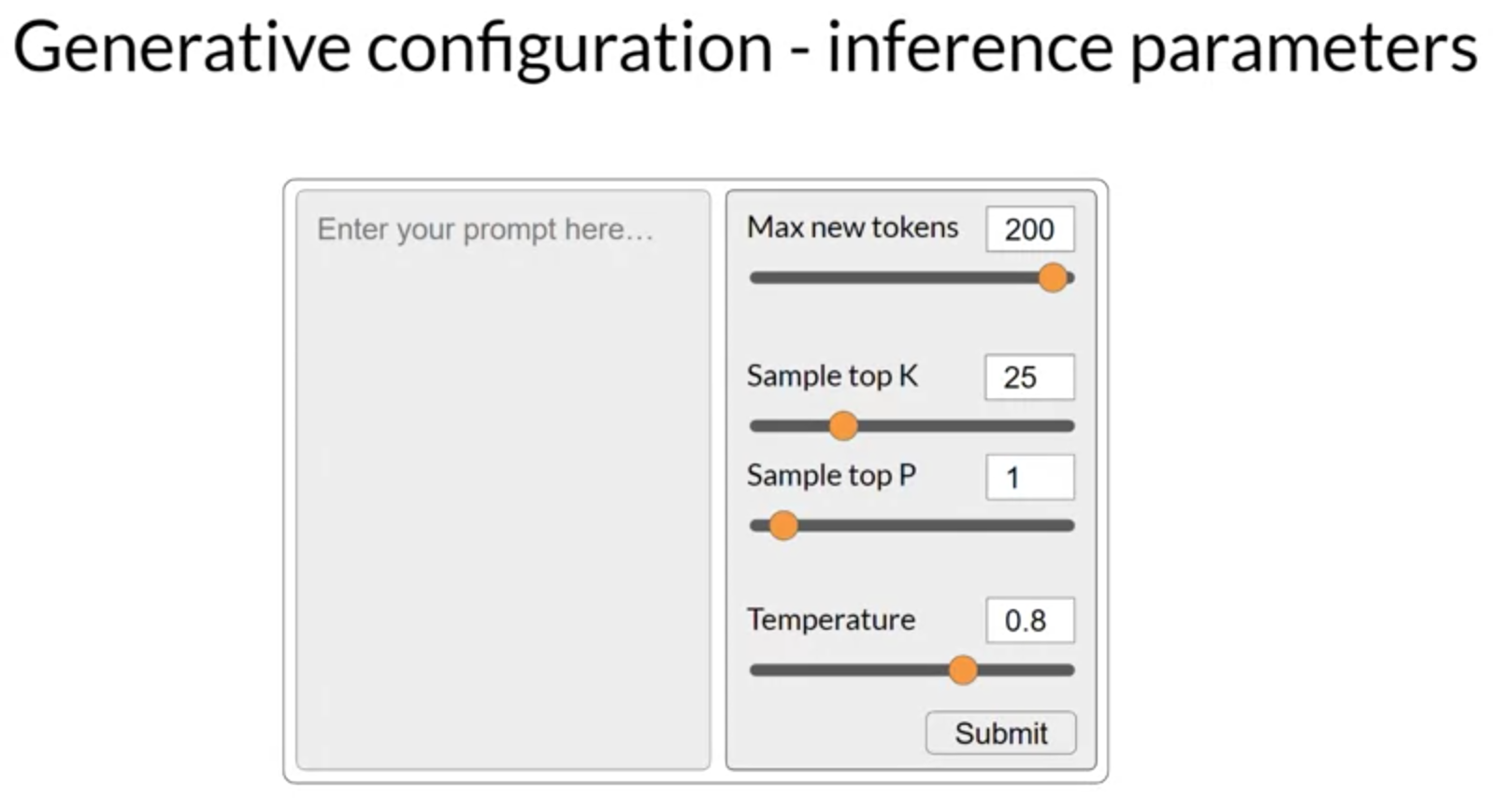
가장 간단한 이러한 매개변수 중 하나는 ‘max new tokens’이며, 이를 사용하여 모델이 생성할 토큰의 수를 제한할 수 있습니다. 이것을 선택 과정을 거치는 횟수에 제한을 두는 것이라고 생각할 수 있습니다. 여기에서는 ‘max new tokens’이 100, 150, 200으로 설정된 예제들을 확인하실 수 있습니다. 하지만 200의 경우 완성 길이가 더 짧다는 점을 주목하세요. 이는 모델이 시퀀스 종료 토큰을 예측하는 등의 다른 중단 조건이 충족되었기 때문입니다. 이것이 ‘max new tokens’이지, 생성된 새 토큰의 엄격한 수가 아님을 기억하세요.

transformer의 softmax 층의 출력은 모델이 사용하는 단어 전체 사전에 걸친 확률 분포입니다. 여기에서는 확률 점수가 옆에 있는 단어들의 선택을 확인할 수 있습니다. 이 곳에는 단지 4개의 단어만 보여주지만, 이것이 완전한 사전에 이르는 목록이라고 생각해 보세요. 대부분의 대형 언어 모델들은 기본적으로 소위 ‘greedy decoding’으로 작동합니다. 이것은 다음 단어 예측의 가장 간단한 형태로, 모델은 항상 가장 높은 확률을 가진 단어를 선택하게 됩니다. 이 방법은 단문 생성에는 아주 잘 작동할 수 있지만, 반복된 단어나 단어 시퀀스의 반복에 취약합니다.

더 자연스럽고 창조적인 텍스트를 생성하고 단어의 반복을 피하고 싶다면, 다른 컨트롤들을 사용해야 합니다. 무작위 샘플링은 변동성을 도입하는 가장 쉬운 방법입니다. 무작위 샘플링을 사용하면, 모델은 매번 가장 확률이 높은 단어를 선택하는 대신, 확률 분포를 사용하여 출력 단어를 무작위로 선택합니다. 예를 들어, 그림에서 단어 ‘바나나’는 확률 점수가 0.02입니다. 무작위 샘플링을 사용하면, 이 단어가 선택될 확률이 2%가 됩니다. 이 샘플링 기법을 사용함으로써, 단어가 반복될 확률이 감소합니다. 그러나 설정에 따라 출력이 너무 창조적일 가능성이 있어, 생성이 논리나 말이 되지 않는 주제나 단어로 흐르게 할 수 있습니다.
일부 구현에서는 greedy를 비활성화하고 무작위 샘플링을 명시적으로 활성화해야 할 수도 있습니다. 예를 들어, 이 실험실에서 사용하는 Hugging Face transformers 구현은 ‘do sample’을 true로 설정해야 합니다. ‘top k’와 ‘top p’ 샘플링 기법을 활용하여 무작위 샘플링을 제한하고 출력이 이치에 맞을 확률을 높여보겠습니다.

‘top k’와 ‘top p’ 설정은 출력이 이치에 맞을 확률을 높이기 위해 무작위 샘플링을 제한하는데 도움을 주는 샘플링 기법입니다. 일부 변동성을 허용하면서 선택 사항을 제한하려면 ‘top k’ 값을 지정할 수 있습니다. 이는 모델에게 가장 높은 확률을 가진 k 토큰 중에서만 선택하도록 지시합니다. 이 예제에서는 k가 3으로 설정되어 있으므로, 모델이 이 세 가지 옵션 중에서만 선택하도록 제한하고 있습니다. 그런 다음 모델은 이러한 옵션 중에서 확률 가중치를 사용하여 선택하며, 이 경우에는 ‘도넛’이 다음 단어로 선택됩니다. 이 방법은 모델이 일정한 무작위성을 가지면서도 고도로 불가능
한 완성 단어의 선택을 방지하도록 도와줍니다. 이는 차례로 텍스트 생성이 합리적으로 들리고 의미가 있게 할 가능성을 높입니다.
다른 한편으로, ‘top p’ 설정을 사용하여 무작위 샘플링을 제한하고 예측의 합계 확률이 p를 초과하지 않도록 할 수 있습니다. 예를 들어, p를 0.3으로 설정하면, 옵션은 ‘케이크’와 ‘도넛’입니다. 왜냐하면 그들의 확률이 각각 0.2와 0.1로, 합하면 0.3이기 때문입니다. 그런 다음 모델은 무작위 확률 가중치 방법을 사용하여 이 토큰들 중에서 선택합니다. ‘top k’에서는 무작위로 선택할 토큰의 수를 지정하고, ‘top p’에서는 모델이 선택하길 원하는 전체 확률을 지정합니다.

모델 출력의 무작위성을 제어하는 데 사용할 수 있는 또 다른 매개변수는 ‘온도’라고 알려져 있습니다. 이 매개변수는 모델이 다음 토큰에 대해 계산하는 확률 분포의 형태에 영향을 미칩니다. 대체로 말하자면, 온도가 높을수록 무작위성이 높고, 온도가 낮을수록 무작위성이 낮습니다. 온도 값은 다음 토큰의 확률 분포 형태에 영향을 미치는 모델의 최종 softmax 층 내에 적용되는 스케일링 요인입니다.
‘top k’와 ‘top p’ 매개변수와 달리, 온도(temperature)를 변경하면 모델이 만들게 될 예측이 실제로 변경됩니다. 온도를 낮은 값, 예를 들어 1보다 작은 값으로 설정하면, softmax 층에서 나오는 확률 분포는 좀 더 뾰족하게 되며, 확률이 더 작은 수의 단어에 집중됩니다. 이것은 여기 표에서 볼 수 있는 푸른 막대에 표시되며, 확률 바 차트를 옆으로 뒤집어 놓은 것이라고 볼 수 있습니다. 대부분의 확률은 ‘케이크’라는 단어에 집중되어 있습니다. 모델은 무작위 샘플링을 사용하여 이 분포에서 선택하고, 그 결과 텍스트는 덜 무작위가 되며, 학습 동안 모델이 학습한 가장 가능성이 높은 단어 시퀀스를 더욱 밀접하게 따르게 됩니다.
대신 온도를 더 높은 값으로 설정하면, 예를 들어 1보다 큰 값으로 설정하면, 모델은 다음 토큰에 대한 더 넓고 평평한 확률 분포를 계산하게 됩니다. 푸른 막대와 비교할 때, 확률은 토큰들 사이에 더 고르게 분포되어 있습니다. 이는 모델이 높은 무작위성을 가진 텍스트를 생성하도록 하고, 출력에서 쿨한 온도 설정에 비해 더 많은 변동성이 나타나도록 합니다. 이는 더 창조적으로 들리는 텍스트를 생성하는 데 도움이 될 수 있습니다.
온도 값을 1로 유지하면, 이는 softmax 함수를 기본값으로 두고 변경하지 않은 확률 분포가 사용됩니다.