과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")




*BLOOM — BigScience Large Open-science Open-Access Multilingual Language Model
BLOOM이란 무엇인가요?
BLOOM은 대형 언어 모델로, LLM이라고도 불리며, 다음과 같이 정의될 수 있습니다:
- 언어 모델은 거대한 수의 매개변수를 통해 훈련되며, BLOOM의 경우 1760억 개의 매개변수를 가지고 있습니다.
- 제로샷 또는 퓨샷 학습으로 결과를 얻을 수 있습니다. 즉, 학습/훈련 없이 또는 단지 몇 문장의 지시만으로도 놀라운 결과를 얻을 수 있습니다.
- LLM은 하드웨어 용량, 처리량, 저장량 등의 측면에서 리소스가 많이 필요합니다.
- 복잡도의 차이에 따라 세부 조정이 가능합니다.
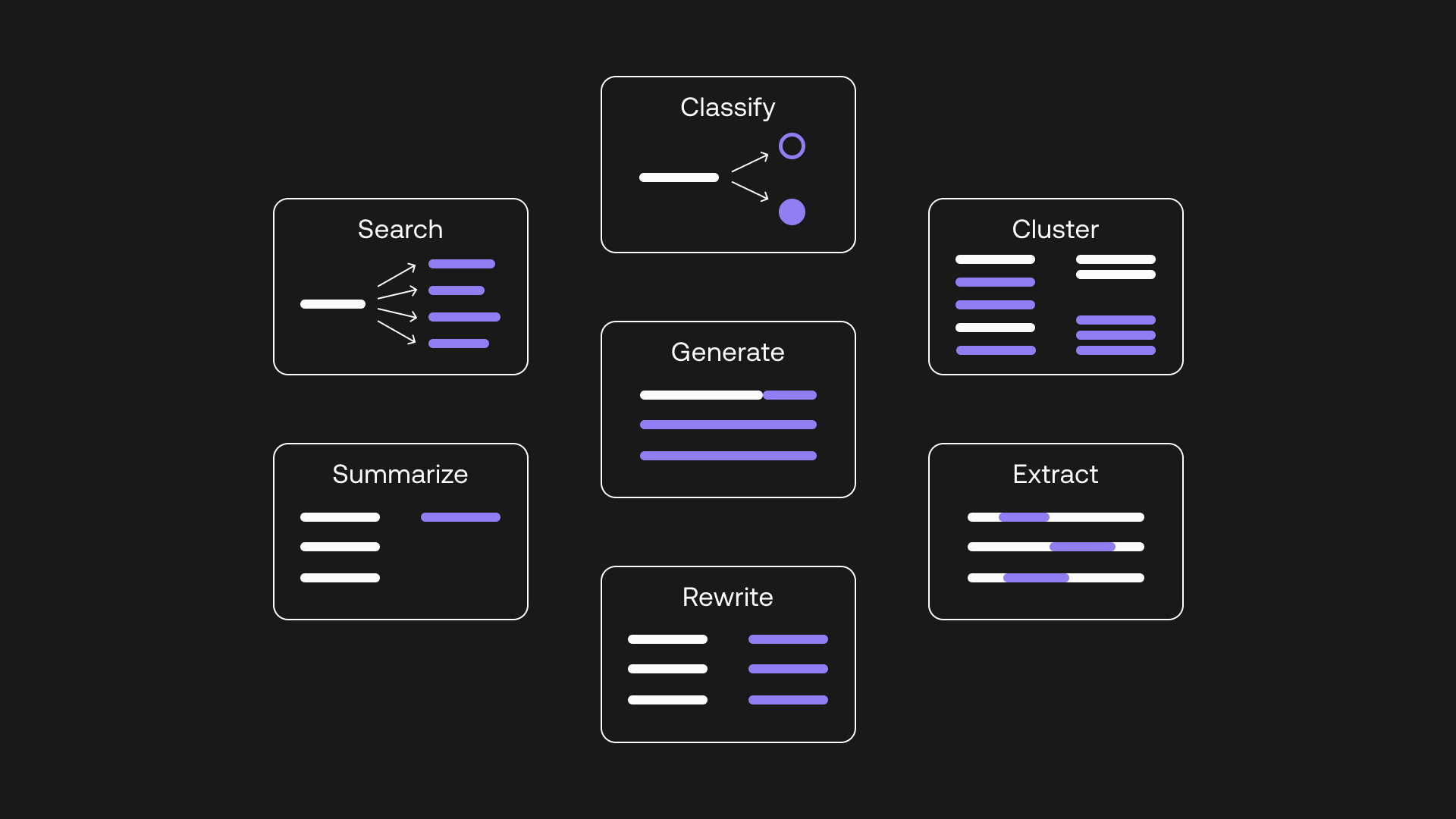
- LLM은 일반적으로 생성(즉, 완성), 요약, 임베딩(클러스터링 및 데이터 시각적 표현), 분류, 의미론적 검색, 언어 번역 등에 사용됩니다.
BLOOM에 대한 상세 정보
BLOOM은 1760억 개의 매개변수를 가지며, NVIDIA AI 플랫폼을 이용해 학습된 세계에서 가장 큰 오픈 사이언스, 공개 접근형 다언어 대형 언어 모델(LLM)입니다. 이는 46개의 언어로 텍스트를 생성할 수 있습니다.
BLOOM은 거대 언어 모델(LLM)로서, 주어진 프롬프트로부터 텍스트를 이어가고 완성하도록 학습되었습니다. 그러므로 본질적으로 이는 텍스트 생성 과정입니다.
완성, 생성, 계속이라는 단어들이 상호 교환적으로 사용되는 것으로 보입니다.
BLOOM은 46개의 언어와 13개의 프로그래밍 언어로 텍스트를 생성할 수 있습니다. 이 모델은 대규모 텍스트 데이터를 산업 수준의 컴퓨팅 자원을 이용하여 학습하였습니다.
BLOOM을 어떻게 사용할 수 있나요?
BLOOM은 생성 엔진이며, 다양한 작업을 수행하는 데 사용할 수 있는 여러 옵션이 있습니다.
BLOOM은 자체적으로 임베딩, 의미론적 검색 또는 분류에 사용될 수는 없습니다. 그러나 BLOOM의 진정한 강점은 (오픈 소스이고 무료로 이용 가능한 것 외에도) 다양한 언어로 텍스트를 생성하는 능력입니다.
텍스트 생성은 여러 가지 방법으로 사용될 수 있습니다.
- 온라인 콘텐츠, 광고, 리뷰, 작성글은 생성(generation)을 통해 만들어질 수 있습니다.
- BLOOM은 명시적으로 훈련되지 않은 텍스트 작업을 수행하는 데 활용될 수 있습니다.
- 이것은 작업을 생성(generation)으로 설정(casting)함으로써 수행될 수 있습니다.
다음은 몇 가지 설정의 예입니다.
아래의 예에서 BLOOM은 의미론적 검색의 한 유형에 사용됩니다. 검은색 텍스트는 사용자 입력으로, LLM 작업이 검색으로 설정됩니다. 사용자 입력이 컨텍스트로 주어지며, 질문이 제시됩니다. 퓨샷 학습의 입력 텍스트는 “답변:” 텍스트로 끝납니다. 설정을 완료하는 것이죠.
검은색 텍스트는 제가 입력한 것이고, 파란색 텍스트는 BLOOM이 생성한 것입니다. 이 생성은 제가 제공한 훈련 데이터의 컨텍스트에 기반합니다.

아래 예시에서는 챗봇 유형의 생성 설정이 수행됩니다. 퓨샷 학습 데이터를 사용하여 검은색 텍스트는 봇과 사용자 사이의 대화를 흉내냅니다. 봇의 응답을 요청하면, 봇은 파란색 텍스트로 컨텍스트에 맞는 응답을 반환합니다.

BLOOM에 어떻게 접근할 수 있나요?
BLOOM에 가장 쉽게 접근하는 방법은 위 이미지에서 볼 수 있는 🤗Hugging Face를 통한 방법입니다. 언어를 설정할 수 있으며, 학습을 위한 사전 설정된 예시가 있고, 샘플링을 설정할 수 있습니다.
그 다음으로는 Spaces가 있습니다.
🤗 Hugging Face spaces는 무엇인가요?
컴퓨터 비전, 오디오 또는 우리의 경우 NLP(대형 언어 모델 포함)와 같은 AI 분야에서, Spaces는 빠르게 회사용 데모를 만들거나 제품을 공개하거나 포트폴리오를 알리는 데 적합합니다.
모든 Spaces는 사용자 프로필이나 조직 프로필과 연관되어 있습니다.
예를 들어, Meta AI의 NLLB 모델로 놀고 싶다면, 모델에 접근하고 space를 통해 사용할 수 있습니다.
아래는 현재 사용 가능한 BLOOM spaces의 목록입니다.

🤗Hugging Face Inference API를 통해 BLOOM에 접근하기
🤗Hugging Face 추론 API를 사용하면, 보다 구체적인 POC 또는 MVP 시나리오로 빠르고 쉽게 나아갈 수 있습니다.
비용 임계값이 매우 낮으며, 커뮤니티 지원을 통해 매월 최대 30,000개의 입력 문자를 무료로 Inference API를 시도해 볼 수 있습니다.
다음 단계는 월 9달러의 Pro 계획입니다. 심지어 남아프리카인에게도 이는 낮은 금액입니다 🙂. 이를 통해 커뮤니티에서 인정받을 수 있으며, AutoTrain, 가속된 추론 API를 통해 쉽게 모델을 훈련시킬 수 있고, 가장 중요한 것은, 텍스트 입력 작업에 대해:
- 월 1백만 개의 무료 입력 문자
- 그 다음으로, CPU에서 월 $10 / 1백만 문자.
- 그리고 GPU에서 월 $50 / 1백만 문자
- 즉시 사용 가능한 모델 핀
- 커뮤니티 지원
추론 API에 대해 여기에서 읽어볼 수 있습니다. 완전한 문서는 여기에서 찾아볼 수 있습니다.

결론
거대 언어 모델(Large Language Models, LLM)에 대해 고려해야 할 몇 가지 사항이 있습니다:
- 호스팅 및 처리에 대한 요구 사항은 주어진 것입니다. 그러나 엣지 설치는 더욱 중요해질 것이며, 이는 가까운 미래에 큰 도약이 이루어질 영역입니다.
- 미세 조정이 아직 부족합니다. LLM은 제로샷과 퓨샷 학습 영역에서 독특한 능력을 가지고 있습니다. 그러나 고급 노코드에서 로우코드로의 미세 조정이 필요합니다.
- 오픈 소스는 좋지만, 호스팅(디스크 공간과 처리), 서비스, API 등이 필요합니다. 이들은 비용이 들며, 어떤 LLM도 “무료”가 아닙니다.
- LLM은 생성(완성)generation (completion), 임베딩(클러스터링)embeddings (clustering), 의미론적 검색(semantic search), 엔티티(entity) 추출 등에 사용될 것입니다.
현재 LLM 영역 내에서 이용 가능한 차별화 영역은 다음과 같습니다:
- 커스텀 모델을 만들기 위한 노코드에서 로우코드로의 미세조정 GUI 환경. 이것을 세 번째 단계로 볼 수 있으며, 제로샷에서 퓨샷, 미세 조정으로 진행됩니다.
- 첫 번째 항목과 어느 정도 관련이 있지만, LLM을 구현하고 관리할 수 있는 스튜디오 환경. HumanFirst Studio와 Cohere의 통합은 미래의 비전입니다.
- 거대 언어 모델과 경쟁하는 것은 헛된 일이며, 최선의 방법은 LLM을 활용하고 가치를 더하는 기회를 찾는 것입니다.
- 회사들에게는 이러한 오픈 소스 LLM을 호스팅하고 사용자에게 매우 저렴한 비용으로 제공하는 기회가 있습니다.
- LLM을 활용하고 관련된 서비스와 제품. AI21labs는 유스케이스와 실제 세계 응용 프로그램을 발명하는 데 있어 좋은 일을 하고 있습니다.
- 지역적으로 분산된 가용성 영역은 지연 시간 등을 제거하기 위한 LLM 구현에 있어서 로지컬한 다음 단계로 보입니다.